機器學習的本質思考:Vibe Coding 時代工程師的關鍵決策指南
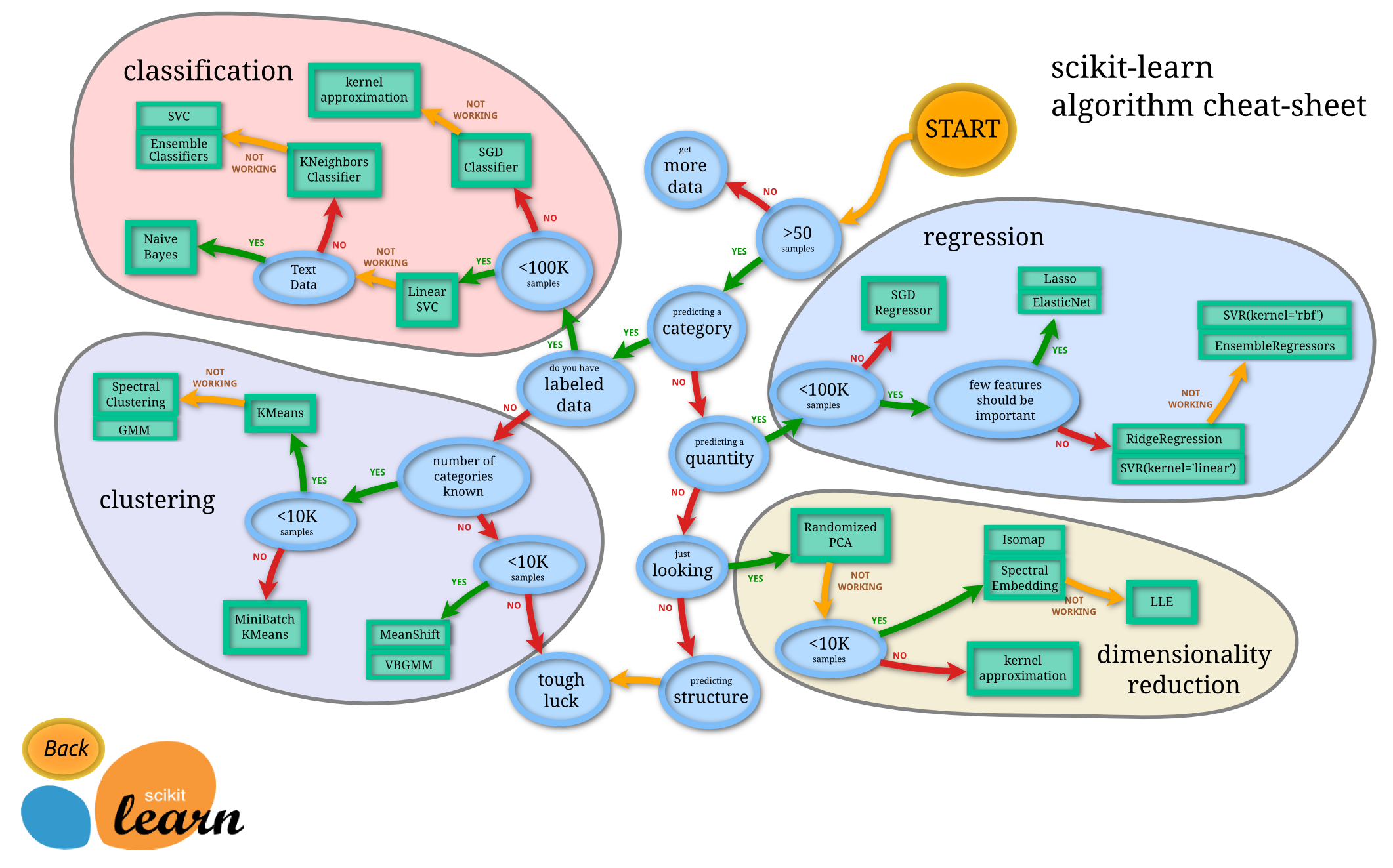
在 AI 輔助開發的時代,Claude 和 ChatGPT 可以幫你寫 code,但「何時用哪個指標」、「為什麼模型會失效」、「如何避開陷阱」這些決策,才是工程師的核心價值。本文聚焦在機器學習中 7 個最容易出錯但影響最深遠的決策點,幫助你從「會用工具」進化到「懂得決策」。
前言:為什麼我們需要理解「為什麼」?
從 Coding 到 Vibing
2024 年以來,軟體開發的範式已經改變。過去我們需要熟記語法、API、設計模式;現在,Claude 和 ChatGPT 能在幾秒內生成符合最佳實踐的程式碼。
但這不代表工程師變得不重要——恰恰相反,決策能力變得更關鍵。
機器學習中的決策陷阱
在機器學習領域,這個差異更加明顯:
AI 可以幫你做的:
- 寫一個 Random Forest 模型的訓練程式碼
- 實作 cross-validation
- 畫出混淆矩陣
AI 無法替你決策的:
- 這個問題該用 Accuracy 還是 F1 Score?
- 為什麼模型在測試集表現很好,部署後卻崩潰?
- 該花時間在特徵工程還是調參?
- 這個模型的弱點在哪裡?會在什麼情況下失效?
這篇文章在聊什麼
這不是教學文,而是我整理機器學習實務中那些「踩過坑才懂」的決策點。
程式碼的部分交給 Claude 就好,這裡想聊的是:
- 評估指標選擇 - 為什麼 Accuracy 會騙人?何時該用 PR-AUC?
- 資料探索策略 - 如何在訓練前發現致命問題?
- 過擬合診斷 - Overfitting 的本質與解法邏輯
- 優化思維差異 - Training 加速 vs Inference 加速的完全不同邏輯
- 商業價值對齊 - Confusion Matrix 背後的商業意義
- 特徵工程決策 - 何時用哪種方法?如何避免 Data Leakage?
- 模型選擇陷阱 - 每個模型的致命弱點與避坑指南
希望這些筆記能幫你少走一些彎路。
Chapter 0: 商業價值對齊 — 先想清楚要解決什麼問題
在深入技術細節前,我們必須先建立一個認知:技術再炫,解決不了真實問題就是零。
為什麼從商業價值開始?
常見的技術導向陷阱
你可能聽過這些對話:
場景 1:模型指標的迷思
數據科學家:「我們的模型 Accuracy 達到 95%!」
產品經理:「太好了!那為什麼使用者留存率沒有提升?」
數據科學家:「...」
場景 2:技術炫技的代價
工程師:「我們用了最新的 Transformer 架構!」
老闆:「推論成本怎麼暴增 10 倍?這樣根本不划算。」
工程師:「但這是 SOTA...」
場景 3:特徵工程的空轉
ML 工程師:「我們做了很酷的特徵工程,用了 50 個新特徵!」
產品團隊:「A/B test 顯示使用者體驗反而變差了。」
ML 工程師:「不可能,模型效能明明提升了...」
正確的思維框架
在開始任何 ML 專案前,先回答三個問題:
-
商業目標是什麼?
- 提升收入?降低成本?改善使用者體驗?
- 具體的數字目標是什麼?
-
ML 要解決什麼問題?
- 注意:不是「ML 能做什麼」,而是「需要解決什麼」
- 問題的核心痛點在哪裡?
-
成本效益如何?
- 開發成本(人力、時間、基礎設施)
- 維護成本(監控、重訓、更新)
- 預期收益(用資料估算,而非拍腦袋)
- ROI 是否值得投入?
從商業問題到 ML 問題:兩個完整案例
案例 1:電商推薦系統
讓我們看一個完整的思考流程:
Step 1: 商業目標
核心目標:提升 GMV (Gross Merchandise Value)
Step 2: 拆解可衡量指標
GMV = 流量 × 點擊率 × 轉換率 × 客單價
↓
可優化的部分:
├─ 點擊率 (CTR) - 推薦更吸引人的商品
├─ 轉換率 (CVR) - 推薦更可能購買的商品
├─ 客單價 (AOV) - 推薦更高價值的商品
└─ 回購率 - 提升長期價值
Step 3: 轉化為 ML 問題
問題定義:
├─ CTR 預測:給定使用者和商品,預測點擊機率
├─ CVR 預測:給定點擊,預測購買機率
└─ 商品排序:根據預測機率和商業規則排序
Step 4: 選擇 Proxy Metrics
Model Metrics(技術指標):
├─ AUC-ROC
├─ Precision@K
└─ NDCG (Normalized Discounted Cumulative Gain)
Business Metrics(商業指標):
├─ GMV
├─ 使用者留存率
└─ 平均購買頻率
Step 5: 關鍵決策點
這裡是最容易出錯的地方:Model Metric 與 Business Metric 不一定正相關。
真實案例:
模型 A:
- AUC = 0.85
- 策略:推薦多樣性高,包含長尾商品
- A/B test 結果:GMV +20%
模型 B:
- AUC = 0.88
- 策略:只推薦熱門商品
- A/B test 結果:GMV +5%
正確決策:選模型 A
為什麼?
- AUC 高不代表商業價值高
- 推薦系統的目標不是「預測準確」,而是「創造價值」
- 長尾商品可能毛利更高、庫存需要清理、或提升使用者黏性
核心洞察:模型指標只是代理(Proxy),商業指標才是目標(Goal)。
案例 2:信用評分系統
Step 1: 商業目標
降低壞帳率,同時維持放款量
注意這裡有個微妙的 Trade-off:
- 如果只追求「降低壞帳」,把所有貸款都拒絕就好(但賺不到錢)
- 如果只追求「提高放款量」,全部核准就好(但壞帳會爆炸)
Step 2: 商業決策框架
關鍵問題:FP 和 FN 的成本各是多少?
定義:
- FP (False Positive):拒絕好客戶(預測會違約,但其實不會)
- FN (False Negative):接受壞客戶(預測不會違約,但其實會)
成本計算:
- FP 成本 = 損失的利息收入 = 平均貸款額 × 利率 × 期限
假設:$100,000 × 5% × 3年 = $15,000
- FN 成本 = 違約損失 = 平均貸款額 × (1 - 回收率)
假設:$100,000 × (1 - 30%) = $70,000
比例:FN 成本是 FP 成本的 4.7 倍
Step 3: 指標選擇
錯誤思維:
「我們要降低壞帳,所以優化 Precision」❌
正確思維:
「FN 的成本是 FP 的 4.7 倍,所以我們應該:
1. 優先優化 Recall(不能漏掉好客戶)
2. 設定 Precision 的下限(控制壞帳在可接受範圍)
3. 根據成本比例調整決策閾值」✅
Step 4: 閾值調整
# 預設閾值 0.5 可能不是最優
# 應該根據成本比例找到最優閾值
# 成本函數
def business_cost(y_true, y_pred_proba, threshold, fp_cost=15000, fn_cost=70000):
y_pred = (y_pred_proba >= threshold).astype(int)
fp = np.sum((y_pred == 1) & (y_true == 0))
fn = np.sum((y_pred == 0) & (y_true == 1))
return fp * fp_cost + fn * fn_cost
# 找出最小化總成本的閾值
thresholds = np.linspace(0, 1, 100)
costs = [business_cost(y_test, y_pred_proba, t) for t in thresholds]
optimal_threshold = thresholds[np.argmin(costs)]
print(f"最優閾值: {optimal_threshold:.3f}")
# 可能輸出:0.23(遠低於預設的 0.5)
核心洞察:機器學習的決策閾值應該由商業成本決定,而非技術預設值。
何時該/不該用 ML?
並非所有問題都適合用機器學習解決。過度使用 ML 會造成不必要的複雜度和成本。
決策框架
1. 問題能用規則解決嗎?
└─ 是 → 先用規則(簡單、可解釋、成本低)
└─ 否 → 繼續
2. 有足夠的資料嗎?
└─ 否(< 1000 筆有標註資料)→ 規則或簡單統計
└─ 是 → 繼續
3. 需要動態調整嗎?
└─ 否(業務邏輯固定且明確)→ 規則引擎可能更好
└─ 是 → 繼續
4. ROI 合理嗎?
└─ ML 總成本 < 預期收益的 1/3 → 值得用 ML
└─ 否 → 重新評估或用更簡單的方法
反面案例:不該用 ML 的情境
| 情境 | 為什麼不該用 ML | 更好的解法 | 真實例子 |
|---|---|---|---|
| 規則明確 | 不需要「學習」 | 正則表達式 + 查表 | 郵遞區號驗證、Email 格式檢查 |
| 簡單邏輯 | if-else 就夠了 | 業務規則引擎 | VIP 客戶判定(消費金額 > $10k) |
| 資料太少 | 無法訓練有效模型 | 專家規則 | 新產品推薦(< 100 筆歷史資料) |
| 需要 100% 準確 | ML 有誤差 | 確定性演算法 | 金額計算、法律條文匹配 |
| 必須可解釋 | 黑盒模型不可接受 | 決策樹或規則 | 醫療診斷、貸款拒絕原因 |
| 維護成本高 | 需要持續重訓、監控 | 靜態規則 | 內部工具的異常偵測 |
正面案例:適合用 ML 的情境
反過來,以下情境 ML 能發揮價值:
-
模式複雜且動態變化
- 例:詐欺偵測(詐騙手法不斷演變)
- 規則系統無法跟上變化速度
-
有大量標註資料
- 例:影像分類(ImageNet 百萬張圖)
- 人工規則難以窮舉所有情況
-
需要個人化
- 例:推薦系統(每個使用者偏好不同)
- 通用規則無法滿足個別需求
-
人類難以明確定義規則
- 例:自然語言理解
- 語言的多義性、上下文依賴難以窮舉
成功案例:Spotify Discover Weekly
讓我們看一個「商業價值對齊」做得很好的例子。
背景
Spotify 的「Discover Weekly」是每週一推薦 30 首使用者可能喜歡的新歌。
商業對齊
核心目標:使用者留存率 + 聽歌時長
↓
可衡量的 Metrics:
├─ 每週活躍用戶數(WAU)
├─ Discover Weekly 播放完成率
├─ 新歌探索比例
└─ 訂閱續約率
↓
商業價值:
留存提升 → 訂閱收入增加 + 廣告收入增加
技術選擇
不是用最炫的技術,而是用「夠好且可靠」的技術:
├─ 協同過濾(Collaborative Filtering)
├─ 內容推薦(Audio Features)
└─ 混合模型
決策邏輯:
├─ Latency 不敏感(週更新,非即時)
├─ 成本可控(Batch prediction,不需要即時推論)
└─ 可解釋性高(使用者信任度高)
持續驗證
不只看 Model Metrics(AUC, Precision),更看 Business Metrics:
├─ A/B test 驗證推薦效果
├─ 使用者調查(質性分析)
└─ 長期追蹤留存率變化
為什麼成功?
- 商業目標明確:不是「推薦準確度」,而是「使用者留存」
- 技術務實:不追求 SOTA,而是「有效且可靠」
- 持續驗證:Model Metric 改善 ≠ Business Metric 改善,必須驗證
核心原則
在進入技術細節前,記住這三句話:
-
「模型指標只是代理,商業指標才是目標」
- 不要為了 Accuracy 犧牲業務價值
- A/B test 是唯一的真理
-
「最簡單能 work 的方案,就是最好的方案」
- 不要為了技術而技術
- 複雜度是負債,不是資產
-
「持續驗證,快速迭代」
- Model Metric 改善 ≠ Business Metric 改善
- 上線後持續監控,隨時準備調整
Chapter 1: 模型評估指標 — 選錯指標,全盤皆輸
商業目標對齊後,下一步是選擇正確的評估指標。這是機器學習中最容易出錯、但影響最深遠的決策之一。
為什麼 Accuracy 會騙人?
詐欺檢測的惡夢
想像你在開發一個信用卡詐欺檢測系統:
# 資料分布
total_transactions = 100,000
fraud_transactions = 100 # 只有 0.1% 是詐欺
normal_transactions = 99,900
# 「愚蠢」的模型:全部預測為「正常」
y_true = [0] * 99900 + [1] * 100
y_pred = [0] * 100000 # 全部預測為 0(正常)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_true, y_pred)
print(f"Accuracy: {accuracy:.2%}")
# 輸出:99.90%
結果:Accuracy 99.9%!看起來很厲害,對吧?
但實際上:這個模型完全沒用,它連一筆詐欺都抓不到!
問題出在哪?
Accuracy 的公式:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
當資料極度不平衡時(99.9% 正常,0.1% 詐欺):
- TN(正確預測正常)= 99,900 → 佔比極大
- TP(正確預測詐欺)= 0 → 但對 Accuracy 影響很小
核心洞察:在不平衡資料中,Accuracy 被多數類「綁架」了。
混淆矩陣:理解模型行為的基石
所有分類指標都源自混淆矩陣(Confusion Matrix):
Predicted
Positive Negative
Actual Pos TP FN
Neg FP TN
定義:
- TP (True Positive):正確預測為正類
- FP (False Positive):錯誤預測為正類(Type I Error,誤報)
- FN (False Negative):錯誤預測為負類(Type II Error,漏報)
- TN (True Negative):正確預測為負類
實際案例:詐欺檢測
Predicted
Fraud Normal
Actual Fraud [50] [50] ← 抓到 50 個真詐欺,漏掉 50 個
Normal [100] [99800] ← 誤判 100 個正常交易
從這個矩陣,我們能看出:
- Recall = 50%:真詐欺案件,只抓到一半
- Precision = 33%:模型說是詐欺的,只有 1/3 是真的
- Accuracy = 99.85%:看起來很高,但其實沒什麼意義
核心指標的數學直覺
Precision(精確率)
公式:
Precision = TP / (TP + FP)
直覺:「模型說『是』的時候,有多少是真的?」
實務意義:
- 高 Precision → 模型說「是」時很可靠
- 低 Precision → 模型亂槍打鳥,很多誤報
何時優化 Precision?
當 False Positive 代價很高 時:
| 場景 | FP 的代價 | 為什麼要優化 Precision |
|---|---|---|
| 垃圾郵件分類 | 正常郵件被誤判 → 使用者錯過重要信件 | 寧可漏掉一些垃圾郵件 |
| 醫療診斷(某些情境) | 誤診導致不必要的治療(副作用、花費) | 減少過度治療 |
| 推薦系統 | 推薦不相關商品 → 使用者體驗變差 | 只推薦有把握的 |
案例:郵件分類
# 場景:1000 封郵件,100 封垃圾郵件
# 模型 A:高 Recall,低 Precision
true_spam = 100
predicted_spam = 200
tp = 95 # 抓到 95 封垃圾郵件
fp = 105 # 但誤判了 105 封正常郵件
precision_A = 95 / 200 = 0.475 # 只有 47.5% 是真垃圾郵件
recall_A = 95 / 100 = 0.95
# 使用者抱怨:「為什麼我的重要郵件被丟到垃圾桶!」
決策:這種情境應該提高 Precision,寧可漏掉一些垃圾郵件,也不要誤殺正常郵件。
Recall(召回率 / Sensitivity / True Positive Rate)
公式:
Recall = TP / (TP + FN)
直覺:「所有真正的正類樣本中,模型找到了多少?」
實務意義:
- 高 Recall → 模型很少「漏掉」真正的陽性案例
- 低 Recall → 模型會遺漏很多重要案例
何時優化 Recall?
當 False Negative 代價很高 時:
| 場景 | FN 的代價 | 為什麼要優化 Recall |
|---|---|---|
| 癌症篩檢 | 漏掉真正的患者 → 延誤治療,危及生命 | 不能漏掉任何一個 |
| 詐欺檢測 | 漏掉真詐欺 → 金錢損失 | 寧可多審查一些 |
| 火災警報 | 漏掉真火災 → 生命財產損失 | 寧可多警報 |
| 搜尋引擎 | 漏掉相關結果 → 使用者找不到資訊 | 召回所有相關結果 |
案例:癌症篩檢
# 場景:1000 人篩檢,10 人有癌症
# 模型 B:高 Precision,低 Recall
true_cancer = 10
predicted_cancer = 5
tp = 5 # 抓到 5 個真患者
fn = 5 # 但漏掉了 5 個!
recall_B = 5 / 10 = 0.5 # 只找到一半的患者
precision_B = 5 / 5 = 1.0 # 但預測是癌症的 100% 正確
# 醫生的憤怒:「有 5 個患者被漏掉,他們可能會錯過治療黃金期!」
決策:這種情境應該提高 Recall,寧可多一些誤報(再進一步檢查),也不能漏掉真正的患者。
F1 Score:平衡 Precision 與 Recall
公式:
F1 = 2 × (Precision × Recall) / (Precision + Recall)
這是 Precision 和 Recall 的調和平均數(Harmonic Mean)。
為什麼用調和平均而非算術平均?
讓我們看一個例子:
# 情況 1:極端不平衡
precision_1 = 1.0
recall_1 = 0.1
arithmetic_mean_1 = (1.0 + 0.1) / 2 = 0.55
harmonic_mean_1 = 2 * (1.0 * 0.1) / (1.0 + 0.1) = 0.18
# 情況 2:相對平衡
precision_2 = 0.8
recall_2 = 0.7
arithmetic_mean_2 = (0.8 + 0.7) / 2 = 0.75
harmonic_mean_2 = 2 * (0.8 * 0.7) / (0.8 + 0.7) = 0.747
觀察:
- 當兩個數值差距大時,調和平均數會接近較小的那個(0.18 vs 0.55)
- 當兩個數值接近時,兩種平均數差不多(0.747 vs 0.75)
核心洞察:調和平均數會懲罰極端不平衡。
直覺類比:
- 算術平均:學生一科 100 分,另一科 10 分 → 平均 55 分(及格)
- 調和平均:學生一科 100 分,另一科 10 分 → F1 = 18 分(不及格)
你不能靠一科滿分掩蓋另一科不及格。
何時使用 F1 Score?
- 當 Precision 和 Recall 都重要,且無法明確判斷誰更重要時
- 當類別不平衡,但 FP 和 FN 的代價相近時
- 作為一個「初步評估」的綜合指標
Imbalanced Data 的致命陷阱
ROC-AUC 的虛高問題
ROC Curve 的定義:
- X 軸:False Positive Rate (FPR) = FP / (FP + TN)
- Y 軸:True Positive Rate (TPR / Recall) = TP / (TP + FN)
- AUC:曲線下面積,範圍 [0, 1],隨機猜測 = 0.5
看起來很合理,有什麼問題?
讓我們看一個極端不平衡的例子:
# 極度不平衡:99% negative, 1% positive
from sklearn.metrics import roc_auc_score, average_precision_score
import numpy as np
y_true = np.array([0] * 990 + [1] * 10)
y_scores = np.concatenate([
np.random.uniform(0.1, 0.4, 990), # negative 的分數較低
np.random.uniform(0.3, 0.7, 10) # positive 的分數中等(弱模型)
])
roc_auc = roc_auc_score(y_true, y_scores)
pr_auc = average_precision_score(y_true, y_scores)
print(f"ROC-AUC: {roc_auc:.3f}") # 可能 0.65-0.75
print(f"PR-AUC: {pr_auc:.3f}") # 可能 0.15-0.25
為什麼 ROC-AUC 虛高?
關鍵在 FPR 的分母:
FPR = FP / (FP + TN)
當負類樣本極多時(TN 很大):
- 即使 FP 很大,FPR 也會被稀釋
- ROC 曲線看起來還不錯
但 Precision 直接反映 FP 的影響:
Precision = TP / (TP + FP)
真實案例對比:
模型預測結果:
TP = 8(抓到 8 個正類)
FP = 100(誤判 100 個負類)
FN = 2(漏掉 2 個正類)
TN = 890(正確預測 890 個負類)
ROC 指標:
TPR (Recall) = 8 / 10 = 0.8
FPR = 100 / 990 = 0.10 ← 看起來還好(只有 10%)
→ ROC-AUC 可能有 0.7-0.8
Precision-Recall 指標:
Precision = 8 / 108 = 0.074 ← 只有 7.4% 是真的!
Recall = 0.8
→ PR-AUC 可能只有 0.2-0.3
核心洞察:ROC-AUC 在不平衡資料中會被 TN(大量負類)「撐住」,無法反映真實表現。
決策規則
資料平衡度?
├─ 40%-60%(平衡)→ ROC-AUC
├─ 10%-30%(中度不平衡)→ 兩者都看
└─ < 5%(極度不平衡)→ 必須用 PR-AUC
實務建議:
- 永遠同時看 ROC-AUC 和 PR-AUC
- 不平衡資料以 PR-AUC 為主
- 用 Precision-Recall Curve 檢查不同閾值下的表現
決策框架:如何選擇評估指標?
總結前面的討論,這是一個完整的決策樹:
資料類別平衡嗎?
├─ 是(40%-60%)
│ ├─ FP 和 FN 代價相近?
│ │ ├─ 是 → Accuracy, F1
│ │ └─ 否 → 根據代價選 Precision 或 Recall
│ └─ 需要調整閾值?→ ROC-AUC
│
└─ 否(不平衡)
├─ 不平衡程度?
│ ├─ 輕度(10-30%)→ F1, Weighted F1
│ └─ 極度(< 5%)→ PR-AUC, F1
│
└─ FP vs FN 代價?
├─ FP 代價高 → Precision
├─ FN 代價高 → Recall
└─ 都重要 → F1, PR-AUC
實戰案例:詐欺檢測系統
讓我們完整走一遍決策流程:
Step 1: 資料探索
print(y.value_counts(normalize=True))
# 0 (正常):99.5%
# 1 (詐欺):0.5%
→ 極度不平衡
Step 2: 商業成本分析
FP 成本(誤判正常為詐欺):
- 人工審查成本:$10
- 使用者體驗損失:約 $20
- 小計:$30
FN 成本(漏掉真詐欺):
- 平均詐欺金額:$500
- 追回率:30%
- 實際損失:$350
FN / FP 成本比 = 350 / 30 ≈ 11.7
Step 3: 指標選擇
主要指標:PR-AUC(不平衡資料)
輔助指標:
├─ Precision(控制誤報率)
├─ Recall(不能漏太多)
└─ F2 Score(加重 Recall,因為 FN 成本更高)
Step 4: 閾值調整
# 根據成本比例找最優閾值
def business_cost(y_true, y_pred_proba, threshold):
y_pred = (y_pred_proba >= threshold).astype(int)
cm = confusion_matrix(y_true, y_pred)
tn, fp, fn, tp = cm.ravel()
fp_cost = 30
fn_cost = 350
total_cost = fp * fp_cost + fn * fn_cost
return total_cost
# 測試不同閾值
thresholds = np.linspace(0.01, 0.99, 100)
costs = [business_cost(y_test, y_pred_proba, t) for t in thresholds]
optimal_idx = np.argmin(costs)
optimal_threshold = thresholds[optimal_idx]
print(f"最優閾值: {optimal_threshold:.3f}")
print(f"最小總成本: ${costs[optimal_idx]:,.0f}")
Step 5: 監控與迭代
上線後持續監控:
├─ 每日詐欺偵測率
├─ 誤報率
├─ 實際金錢損失
└─ 人工審查工作量
觸發重訓條件:
├─ PR-AUC 下降 > 5%
├─ 詐欺損失增加 > 20%
└─ 資料分布明顯飄移
章節總結
核心原則:
-
Accuracy 會騙人
- 不平衡資料中,Accuracy 毫無意義
- 永遠先檢查資料分布
-
理解 Precision vs Recall
- Precision:「說是的時候,有多少是真的?」
- Recall:「真的陽性,找到了多少?」
- 根據 FP 和 FN 的代價決定優化哪個
-
F1 Score 的真正意義
- 調和平均會懲罰極端不平衡
- 不能靠一個指標高來掩蓋另一個低
-
ROC-AUC vs PR-AUC
- 不平衡資料:ROC-AUC 會虛高,必須用 PR-AUC
- 平衡資料:兩者都可以
-
商業成本才是王道
- 模型指標只是代理
- 決策閾值應由商業成本決定
決策檢查表:
- [] 檢查資料平衡度
- [] 計算 FP 和 FN 的商業成本
- [] 選擇對應的主要指標
- [] 設定輔助指標(多角度評估)
- [] 根據成本調整閾值
- [] 上線後持續監控
Chapter 2: EDA — 訓練模型前該做的功課
很多人一拿到資料就急著訓練模型,結果踩了一堆坑。這章聊聊為什麼要先「看一下資料」。
為什麼需要 EDA?
核心問題:每個演算法都有「隱藏的假設」,不做 EDA 就像矇著眼睛開車。
舉幾個真實慘案:
慘案 1:沒發現資料不平衡
# 你以為的分布:正常
print(y.value_counts())
# 0: 5000
# 1: 5000
# 實際的分布:GG
print(y.value_counts())
# 0: 9950
# 1: 50 ← 只有 0.5%
# 結果:
# - 模型偏向預測 0(多數類)
# - Accuracy 看起來 99%,但完全沒用
# - 浪費三天調參,都是白工
慘案 2:沒發現異常值
# 收入特徵
df['income'].describe()
# mean: 50,000
# std: 20,000
# max: 50,000,000 ← WTF?
# 結果:
# - Linear model 被異常值主導
# - 預測結果完全偏掉
# - 重訓三次才發現是資料問題
慘案 3:沒發現缺失值模式
# 某個重要特徵
missing_rate = df['credit_history'].isnull().mean()
print(f"缺失率: {missing_rate:.1%}")
# 缺失率: 60%
# 而且缺失不是隨機的:
# - 新客戶沒有信用歷史(系統性缺失)
# - 直接填 0 或 mean 都是錯的
# - 應該把「是否有信用歷史」當成一個特徵
EDA 的三大目標
- 發現資料問題:缺失值、異常值、重複資料、資料錯誤
- 理解資料特性:分布、相關性、類別平衡
- 驗證假設:模型適用性、特徵有效性
關鍵檢查項目
檢查 1:類別平衡(最容易忽略但影響最大)
為什麼重要?
- 影響指標選擇(Accuracy 失效)
- 影響模型訓練(Decision Tree 會偏向多數類)
- 影響閾值設定
怎麼檢查?
# 方法 1:統計
print(y.value_counts())
print(y.value_counts(normalize=True))
# 方法 2:視覺化
import matplotlib.pyplot as plt
y.value_counts().plot(kind='bar')
plt.title('類別分布')
plt.show()
決策樹:
類別比例?
├─ 40%-60% → 平衡,正常訓練就好
├─ 20%-40% → 輕度不平衡
│ └─ 考慮:class_weight='balanced'
├─ 5%-20% → 中度不平衡
│ └─ 必須:SMOTE 或調整閾值
└─ < 5% → 極度不平衡
└─ 必須:改用 PR-AUC + F1 + 調整閾值
真實案例:
我曾經在一個詐欺檢測專案上,一開始沒注意到資料是 99.5% 正常、0.5% 詐欺。結果:
- 模型 Accuracy 99.7%(看起來超棒)
- Precision 只有 10%(根本不能用)
- 浪費了一整週調參
後來發現問題後:
- 加上
class_weight='balanced' - 改用 PR-AUC 當主要指標
- 調整閾值到 0.2(而非預設 0.5)
- Precision 提升到 60%,實際可用
檢查 2:特徵分布
為什麼重要?
- 長尾分布 → Linear models 表現差
- 異常值 → 主導梯度方向
- 不同尺度 → 某些演算法會失效(KNN, SVM)
怎麼檢查?
# 統計摘要
print(df.describe())
# 視覺化分布
df.hist(bins=50, figsize=(20,15))
plt.tight_layout()
plt.show()
# 檢查偏態
from scipy.stats import skew
for col in df.select_dtypes(include=['float64', 'int64']).columns:
skewness = skew(df[col].dropna())
if abs(skewness) > 1:
print(f"{col}: skewness = {skewness:.2f} (考慮 log transform)")
決策樹:
分布類型?
├─ 長尾/右偏態(收入、房價)
│ └─ 用 log transformation 或 np.log1p()
├─ 有大量異常值
│ ├─ 可以移除?→ 移除 (如資料錯誤)
│ └─ 不能移除?→ RobustScaler 或 clip
├─ 接近正態分布
│ └─ StandardScaler 就夠了
└─ 尺度差異很大(身高 vs 體重)
└─ StandardScaler 或 MinMaxScaler
實戰案例:房價預測
# 原始分布:右偏態
plt.hist(df['price'], bins=50)
# 大部分在 30-50 萬,但有幾個 500 萬的豪宅
# 問題:
# - Linear regression 被豪宅拉偏
# - R² 只有 0.6
# 解法:log transformation
df['price_log'] = np.log1p(df['price'])
plt.hist(df['price_log'], bins=50)
# 現在接近正態分布
# 結果:
# - R² 提升到 0.85
# - 預測更穩定
檢查 3:缺失值模式
為什麼重要?
- 隨機缺失 vs 系統性缺失(處理方式完全不同)
- 缺失率太高 → 可能要捨棄該特徵
- 缺失本身可能就是一個特徵
怎麼檢查?
# 缺失率統計
missing = df.isnull().sum() / len(df)
missing = missing[missing > 0].sort_values(ascending=False)
print(missing)
# 視覺化缺失模式
import missingno as msno
msno.matrix(df)
plt.show()
# 檢查缺失是否相關
msno.heatmap(df)
plt.show()
決策樹:
缺失率?
├─ < 5%
│ └─ 填補:mean/median/mode
├─ 5%-30%
│ ├─ 隨機缺失?
│ │ └─ 填補 + 可選:加上 is_missing 欄位
│ └─ 系統性缺失?
│ └─ 必須加上 is_missing 作為特徵
└─ > 30%
├─ 重要特徵?→ 想辦法處理(模型預測缺失值)
└─ 不重要?→ 直接捨棄
真實案例:信用評分
# 信用歷史長度
credit_history_missing = df['credit_history'].isnull().mean()
# 60% 缺失
# 分析後發現:
# - 缺失 = 新客戶,沒有信用記錄
# - 這本身就是重要資訊!
# 錯誤做法:
df['credit_history'].fillna(0) # ❌ 把新客戶當成信用差
# 正確做法:
df['has_credit_history'] = (~df['credit_history'].isnull()).astype(int)
df['credit_history'] = df['credit_history'].fillna(0)
# 兩個特徵都保留,模型可以學到「沒有信用記錄」的影響
檢查 4:相關性與多重共線性
為什麼重要?
- 高度相關的特徵造成冗餘(浪費運算)
- 多重共線性讓 Linear model 係數不穩定
怎麼檢查?
# 相關矩陣
import seaborn as sns
corr_matrix = df.corr()
plt.figure(figsize=(12, 10))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0)
plt.show()
# 找高度相關的特徵對
high_corr_pairs = []
for i in range(len(corr_matrix.columns)):
for j in range(i+1, len(corr_matrix.columns)):
if abs(corr_matrix.iloc[i, j]) > 0.9:
high_corr_pairs.append((
corr_matrix.columns[i],
corr_matrix.columns[j],
corr_matrix.iloc[i, j]
))
for feat1, feat2, corr in high_corr_pairs:
print(f"{feat1} - {feat2}: {corr:.3f}")
決策:
相關性 > 0.95?
├─ 是 → 移除其中一個(通常保留更容易解釋的)
└─ 否 → 保留
VIF > 10?(多重共線性)
├─ 是 → 有問題,考慮:
│ ├─ 移除某些相關特徵
│ ├─ PCA 降維
│ └─ 改用 Tree-based models(不受影響)
└─ 否 → OK
實戰案例:
# 發現問題:
# total_rooms 和 total_bedrooms 相關性 0.93
# 分析:
# - 房間多 → 臥室也多(廢話)
# - 兩個特徵資訊重複
# 決策:
# 方法 1:移除一個
df = df.drop('total_bedrooms', axis=1)
# 方法 2:創造新特徵
df['avg_rooms_per_bedroom'] = df['total_rooms'] / df['total_bedrooms']
df = df.drop(['total_rooms', 'total_bedrooms'], axis=1)
# 新特徵更有意義:每個臥室平均有幾個房間
Confusion Matrix 的商業解讀
這部分在 Chapter 1 講過了,但再強調一次:不要只看數字,要算成本。
Predicted
Fraud Normal
Actual Fraud [50] [10] ← 漏掉 10 個,損失 $100k
Normal [20] [920] ← 誤判 20 個,人工審查成本 $2k
重點:
- 計算 FP 和 FN 的實際成本
- 找出最小化總成本的閾值
- 不要用預設的 0.5
EDA 的實戰流程
我自己的 checklist:
# 1. 基本資訊
print(df.info())
print(df.describe())
# 2. 目標變數分布
print(y.value_counts(normalize=True))
y.value_counts().plot(kind='bar')
# 3. 缺失值
missing = df.isnull().sum() / len(df)
print(missing[missing > 0])
# 4. 數值特徵分布
df.hist(bins=50, figsize=(20,15))
# 5. 類別特徵分布
for col in df.select_dtypes(include=['object']).columns:
print(f"\n{col}:")
print(df[col].value_counts()[:10])
# 6. 相關性
sns.heatmap(df.corr(), annot=True)
# 7. 異常值檢查
from scipy import stats
z_scores = stats.zscore(df.select_dtypes(include=['float64', 'int64']))
outliers = (abs(z_scores) > 3).sum(axis=0)
print(f"異常值數量:\n{outliers[outliers > 0]}")
小結
核心觀念:
-
不做 EDA 就訓練 = 浪費時間
- 資料問題比模型選擇更重要
- 10 分鐘的 EDA 能省下 10 小時的調參
-
類別不平衡是最容易忽略的問題
- 永遠先檢查
y.value_counts() - 不平衡時,Accuracy 毫無意義
- 永遠先檢查
-
視覺化是最便宜的 debug 工具
- 一張圖勝過 100 行統計數字
df.hist()和sns.heatmap()是必備
-
缺失值要看模式,不是亂填
- 系統性缺失本身就是資訊
- 不要無腦填 mean/median
Chapter 3: Overfitting vs Underfitting — 模型的兩種死法
這是機器學習最核心的概念,但很多人只知道名詞,不懂本質。
本質理解
Underfitting (High Bias)
本質:模型太簡單,連訓練資料的模式都學不好。
比喻:
- 用直線擬合曲線
- 用小學數學解微積分題
- 用「身高」預測「收入」(太簡化了)
症狀:
Train Error: 高
Test Error: 也高
兩者差距: 小
結論:模型根本學不到東西
實際例子:
# 真實關係:二次曲線
X = np.linspace(0, 10, 100).reshape(-1, 1)
y = 2 * X**2 + 3 * X + 5 + noise
# 用線性模型擬合
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
print(f"Train R²: {model.score(X_train, y_train):.3f}") # 0.65
print(f"Test R²: {model.score(X_test, y_test):.3f}") # 0.63
# 兩個都很低 → Underfitting
Overfitting (High Variance)
本質:模型太複雜,把噪音當成模式學起來了。
比喻:
- 背題目的答案,不懂原理
- 記住每個訓練樣本,沒有泛化能力
- 考古題 100 分,新題目 0 分
症狀:
Train Error: 很低(甚至 0)
Test Error: 很高
兩者差距: 巨大
結論:模型只會背答案,不會舉一反三
實際例子:
# 用高次多項式擬合
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 15 次多項式(過度複雜)
model = make_pipeline(PolynomialFeatures(15), LinearRegression())
model.fit(X_train, y_train)
print(f"Train R²: {model.score(X_train, y_train):.3f}") # 0.99
print(f"Test R²: {model.score(X_test, y_test):.3f}") # 0.45
# Train 很高,Test 很低 → Overfitting
診斷:Learning Curve
最直觀的診斷工具:畫出 Train Error vs Test Error
from sklearn.model_selection import learning_curve
train_sizes, train_scores, test_scores = learning_curve(
model, X, y,
train_sizes=np.linspace(0.1, 1.0, 10),
cv=5
)
plt.plot(train_sizes, train_scores.mean(axis=1), label='Train')
plt.plot(train_sizes, test_scores.mean(axis=1), label='Test')
plt.xlabel('Training Set Size')
plt.ylabel('Score')
plt.legend()
plt.show()
三種典型曲線:
情況 1: Underfitting
Train ————————— (低且平)
Test ————————— (低且平)
→ 兩條線都低且接近
→ 增加資料也沒用,需要更複雜的模型
情況 2: Overfitting
Train ————————— (高)
Test \_____/ (低,有大 gap)
→ Train 高,Test 低,gap 很大
→ 需要 Regularization 或更多資料
情況 3: Good Fit
Train ————————— (高)
Test ————————— (高,gap 小)
→ 兩條線都高且接近
→ 可以嘗試更複雜的模型看能否再提升
解法與原理
解 Overfitting
原理:限制模型複雜度,或增加資料多樣性
| 方法 | 為什麼有效? | 何時使用 | 實際效果 |
|---|---|---|---|
| L1/L2 Regularization | 懲罰大權重,逼迫模型簡化 | Linear models, Neural Networks | 通常降低 5-15% overfit |
| Dropout | 隨機關閉神經元,防止共適應 | Neural Networks | 深度模型必備,降低 10-20% overfit |
| Early Stopping | 在驗證集錯誤上升前停止 | 所有迭代式模型 | 簡單有效,省時間 |
| Data Augmentation | 增加資料多樣性 | 影像、文字、音訊 | 效果最好,但費時 |
| Ensemble | 多個模型平均,降低變異 | Tree models (Random Forest) | Bagging 能降低 20-30% variance |
| 減少特徵 | 降低模型複雜度 | Feature selection | 特徵太多時有效 |
| 更多資料 | 讓模型看到更多樣本 | 任何情況 | 最根本的解法,但通常不容易取得 |
實戰案例:Regularization
from sklearn.linear_model import Ridge, Lasso
# 沒有 regularization:overfitting
model = LinearRegression()
model.fit(X_train, y_train)
print(f"Train: {model.score(X_train, y_train):.3f}") # 0.95
print(f"Test: {model.score(X_test, y_test):.3f}") # 0.68
# L2 Regularization (Ridge)
model = Ridge(alpha=1.0) # alpha 越大,懲罰越重
model.fit(X_train, y_train)
print(f"Train: {model.score(X_train, y_train):.3f}") # 0.88
print(f"Test: {model.score(X_test, y_test):.3f}") # 0.82
# Train 降了一點,但 Test 提升了 → 成功!
核心邏輯:
- Regularization 會讓 Train Error 稍微上升(模型被「限制」了)
- 但 Test Error 會明顯下降(泛化能力變好)
- 這個 trade-off 是值得的
解 Underfitting
原理:增加模型複雜度,或改善特徵
| 方法 | 為什麼有效? | 何時使用 |
|---|---|---|
| 更複雜的模型 | 增加學習能力 | Linear → Polynomial, Tree → Deep Tree |
| 更多特徵 | 提供更多資訊給模型 | Feature Engineering |
| 減少 Regularization | 放鬆限制 | alpha 太大時 |
| 訓練更久 | 給模型更多學習機會 | Neural Networks (增加 epochs) |
| Polynomial Features | 捕捉非線性關係 | Linear models 遇到非線性資料 |
實戰案例:
# Underfitting:線性模型 + 二次關係
model = LinearRegression()
print(f"Test R²: {model.score(X_test, y_test):.3f}") # 0.65
# 解法 1:加入多項式特徵
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
model = LinearRegression()
model.fit(X_train_poly, y_train)
print(f"Test R²: {model.score(X_test_poly, y_test):.3f}") # 0.89
# 解法 2:換更複雜的模型
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100)
model.fit(X_train, y_train)
print(f"Test R²: {model.score(X_test, y_test):.3f}") # 0.91
實戰決策流程
# Step 1: 訓練模型
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(f"Train: {train_score:.3f}")
print(f"Test: {test_score:.3f}")
print(f"Gap: {train_score - test_score:.3f}")
# Step 2: 診斷
if train_score < 0.7 and test_score < 0.7:
print("→ Underfitting")
print(" 建議:")
print(" 1. 增加模型複雜度")
print(" 2. Feature Engineering")
print(" 3. 減少 Regularization")
elif train_score > 0.9 and (train_score - test_score) > 0.15:
print("→ Overfitting")
print(" 建議:")
print(" 1. 加 Regularization")
print(" 2. Early Stopping")
print(" 3. 更多資料")
print(" 4. Feature Selection")
else:
print("→ Good Fit")
print(" 可以嘗試更複雜模型看能否再提升")
小結
記住這些:
-
Underfitting = 模型太笨
- 症狀:Train 和 Test 都差
- 解法:增加複雜度
-
Overfitting = 模型背題目
- 症狀:Train 好,Test 差
- 解法:限制複雜度或增加資料
-
Learning Curve 是最好的診斷工具
- 一張圖就能看出問題
- 不要只看單一數字
-
Regularization 是對抗 Overfit 的第一選擇
- 簡單、有效、通用
- 幾乎所有模型都能用
Chapter 4: Training 加速 vs Inference 加速 — 完全不同的優化邏輯
很多人搞混這兩個,結果優化方向錯誤。先理解差異,才知道該優化什麼。
核心差異
| 維度 | Training | Inference |
|---|---|---|
| 目標 | 盡快完成訓練,快速迭代實驗 | 即時回應使用者 |
| 頻率 | 每週/每月一次 | 每秒數千次 |
| 資源 | 可用 GPU/TPU,成本可控 | 通常用 CPU,成本敏感 |
| Latency 要求 | 分鐘到小時級別 OK | 毫秒到秒級別 |
| 優化重點 | 總時間(wall-clock time) | 單次推論時間 |
直覺理解:
- Training:馬拉松,重點是「跑完」
- Inference:短跑,重點是「每次都快」
Training 加速
為什麼要加速 Training?
真實情境:
實驗 1:Baseline model
→ 訓練時間:2 小時
→ 結果:Accuracy 85%
想嘗試的實驗:
- 不同的特徵組合(10 種)
- 不同的超參數(20 種)
- 不同的模型架構(5 種)
總共需要測試:10 × 20 × 5 = 1000 次
總時間:2 小時 × 1000 = 2000 小時 = 83 天
如果能加速到 10 分鐘:
10 分鐘 × 1000 = 167 小時 = 7 天
核心問題:Training 慢 → 實驗少 → 模型差
加速策略
策略 1: Mixed Precision Training (FP16)
原理:用 16-bit 浮點數代替 32-bit
# PyTorch 範例
from torch.cuda.amp import autocast, GradScaler
model = MyModel().cuda()
optimizer = torch.optim.Adam(model.parameters())
scaler = GradScaler()
for data, target in train_loader:
optimizer.zero_grad()
# 自動混合精度
with autocast():
output = model(data)
loss = criterion(output, target)
# 縮放loss,避免underflow
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
效果:
- 記憶體減半(可用更大的 batch)
- 速度提升 2-3x
- 幾乎無精度損失
何時用:
- GPU 訓練(需要 Tensor Cores 支援)
- 深度學習模型
- 記憶體不夠大 batch 時
策略 2: Gradient Accumulation
原理:累積多個小 batch 的梯度,模擬大 batch
# 真實 batch size = accumulation_steps × mini_batch_size
accumulation_steps = 4
optimizer.zero_grad()
for i, (data, target) in enumerate(train_loader):
output = model(data)
loss = criterion(output, target)
# 梯度累積
loss = loss / accumulation_steps
loss.backward()
# 每 N 步才更新一次
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
為什麼有效?
- 大 batch 通常訓練更快(GPU 利用率高)
- 但記憶體不夠 → 用累積模擬
何時用:
- GPU 記憶體不足
- 想用大 batch 但記憶體有限
策略 3: 資料載入優化
問題:GPU 在等資料,很浪費
# 慢的寫法
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# 快的寫法
train_loader = DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=4, # 多線程載入
pin_memory=True, # 加速 CPU → GPU 傳輸
prefetch_factor=2 # 預先載入
)
效果:
- 減少 GPU 等待時間
- 整體加速 20-50%
策略 4: 更好的優化器
# 標準 Adam
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# AdamW(更快收斂,Transformer 必備)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=0.001,
weight_decay=0.01
)
# LAMB(大 batch 訓練專用)
# 用在 BERT 等大模型
為什麼有效?
- 更好的優化器 → 更快收斂 → 更少 epochs
- AdamW:修正 weight decay,收斂更穩定
- LAMB:專為大 batch 設計
Inference 加速
為什麼要加速 Inference?
真實場景:
推薦系統:
- 每秒 10,000 次推論
- 每次推論需要 100ms
- 需要 10,000 × 0.1 = 1000 秒 ≈ 17 分鐘處理一秒的請求
→ GG,系統癱瘓
如果加速到 10ms:
- 10,000 × 0.01 = 100 秒
- 可以用 10 台機器平行處理
→ OK,可行
成本計算:
假設:
- 每天 1 億次推論
- CPU instance: $0.05/hour
- 每次推論 100ms → 需要 2778 小時 → $138.9/天
- 每次推論 10ms → 需要 278 小時 → $13.9/天
加速 10 倍 = 省 $125/天 = $45,625/年
核心問題:Inference 慢 → 成本高 or 使用者體驗差
加速策略
策略 1: Quantization (量化)
原理:FP32 → INT8,模型大小減 4 倍
import torch
# 原始模型 (FP32)
model = MyModel()
model.eval()
# Dynamic Quantization(最簡單)
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear}, # 量化哪些層
dtype=torch.qint8
)
# 比較大小
torch.save(model.state_dict(), 'model.pth')
torch.save(quantized_model.state_dict(), 'quantized_model.pth')
# 原始:100 MB
# 量化後:25 MB
效果:
- 模型大小減少 4 倍
- 推論速度提升 2-4 倍
- 精度損失 < 1%(通常可接受)
何時用:
- 部署到邊緣設備(手機、IoT)
- CPU 推論
- 記憶體/頻寬受限
策略 2: Pruning (剪枝)
原理:移除不重要的權重
import torch.nn.utils.prune as prune
# 對 Linear layer 剪枝
prune.l1_unstructured(
module=model.fc1,
name='weight',
amount=0.3 # 移除 30% 的權重
)
# 檢查稀疏度
print(f"Sparsity: {100. * float(torch.sum(model.fc1.weight == 0)) / float(model.fc1.weight.nelement()):.1f}%")
效果:
- 移除 30-50% 權重
- 速度提升 1.5-2x
- 精度損失 1-3%
策略 3: Knowledge Distillation (知識蒸餾)
原理:大模型「教」小模型
# Teacher model (大而準)
teacher = LargeModel() # 1GB, Accuracy 95%
teacher.eval()
# Student model (小而快)
student = SmallModel() # 100MB
# 蒸餾訓練
for data, target in train_loader:
# Teacher 的預測(軟標籤)
with torch.no_grad():
teacher_output = teacher(data)
# Student 學習
student_output = student(data)
# Loss = 學 Teacher + 學真實標籤
loss = (
distillation_loss(student_output, teacher_output) +
ce_loss(student_output, target)
)
loss.backward()
optimizer.step()
效果:
- 模型大小減少 5-10 倍
- 速度提升 5-10 倍
- 保留 95% 的準確度
經典案例:DistilBERT
- 原始 BERT:340M 參數
- DistilBERT:66M 參數(減少 40%)
- 速度:快 60%
- 準確度:保留 97% 性能
策略 4: Batch Prediction(批次推論)
原理:非即時場景用批次處理
# 即時推論(慢)
for user in users:
recommendation = model.predict(user)
send_to_user(recommendation)
# 批次推論(快)
# 每小時批次處理一次
all_users = get_all_users()
recommendations = model.predict_batch(all_users) # 一次推論
cache_results(recommendations)
# 使用者查詢時直接從 cache 拿
效果:
- GPU 利用率高(大 batch)
- 成本降低 70-90%
- Latency:從「毫秒」變成「分鐘」(但很多場景可接受)
適用場景:
- 推薦系統(每小時更新)
- 報表生成(每天一次)
- 離線分析
策略 5: Caching(快取)
原理:重複查詢直接回傳
from functools import lru_cache
import hashlib
class ModelWithCache:
def __init__(self, model):
self.model = model
self.cache = {}
def predict(self, features):
# 用 hash 當 key
key = hashlib.md5(str(features).encode()).hexdigest()
if key not in self.cache:
self.cache[key] = self.model.predict(features)
return self.cache[key]
何時有效?
- 重複查詢多(如熱門商品推薦)
- 特徵空間有限(如類別變數為主)
決策樹
需要即時回應?
├─ 是
│ ├─ Latency < 10ms?
│ │ ├─ 是 → Quantization + Pruning + Cache
│ │ └─ 否(< 100ms)→ Quantization + Cache
│ └─ 資源有限?(邊緣設備)
│ └─ 是 → Knowledge Distillation
│
└─ 否(可以非即時)
└─ Batch Prediction(成本最低)
小結
記住這些:
-
Training vs Inference 的優化邏輯完全不同
- Training:總時間,用得起 GPU
- Inference:單次時間,成本敏感
-
Training 加速:
- FP16:簡單有效,必用
- 資料載入優化:低垂的果實
- 更好的優化器:AdamW
-
Inference 加速:
- Quantization:4 倍壓縮,2-4 倍加速
- Knowledge Distillation:10 倍加速,保留 95% 效能
- Batch Prediction:非即時場景的最佳選擇
-
成本影響巨大:
- Inference 成本是長期的
- 加速 10 倍 = 省 90% 成本
- 值得投資時間優化
Chapter 5: Feature Engineering — 何時用哪種方法?
這章不講「怎麼做」(Claude 會),而是講「何時用」與「為什麼」。
核心問題:Feature Engineering 要解決什麼?
本質:把原始資料轉換成模型能理解的語言。
三大目標:
- 降低模型學習難度
# 原始:身高 170cm, 體重 70kg
# 模型需要自己學會:BMI = 體重 / (身高²)
# 很難學,因為要學「除法」和「平方」
# Feature Engineering:
df['BMI'] = df['weight'] / (df['height'] / 100) ** 2
# 模型只需要學:BMI 高 → 某種結果
# 簡單多了
- 捕捉領域知識
# 電商:購買日期 2024-01-15
# 模型很難從日期學到「週末消費多」
# Feature Engineering:
df['is_weekend'] = df['date'].dt.dayofweek.isin([5, 6])
# 直接告訴模型「這是週末」
- 處理特殊資料類型
# 問題:23點 vs 0點 數值差 23,但其實只差 1 小時
# Feature Engineering:
df['hour_sin'] = np.sin(2 * np.pi * df['hour'] / 24)
df['hour_cos'] = np.cos(2 * np.pi * df['hour'] / 24)
# 現在 23點 和 0點 在特徵空間中很接近了
決策框架:類別特徵處理
類別特徵是最常遇到的,但處理方式很多種,該怎麼選?
類別數量?
├─ < 10 個(如性別、星期幾)
│ └─ One-Hot Encoding
│
├─ 10-100 個(如城市、部門)
│ ├─ Tree-based models?
│ │ └─ 是 → Label Encoding 就夠了
│ └─ Linear models?
│ └─ 是 → One-Hot Encoding
│
└─ > 100 個(如郵遞區號、User ID)
├─ 有目標變數?
│ └─ 是 → Target Encoding(小心 Data Leakage!)
└─ 否 → Frequency Encoding 或 Hashing
One-Hot Encoding
何時用:
- 類別數 < 10
- 類別之間沒有順序關係
- 用 Linear models 或 Neural Networks
為什麼有效:
- 不引入錯誤的順序關係
- 模型可以獨立學習每個類別的影響
陷阱:
# 類別太多會爆炸
df['city'].nunique() # 500 個城市
pd.get_dummies(df['city']) # 產生 500 個特徵 → GG
Label Encoding
何時用:
- Tree-based models (Random Forest, XGBoost)
- 類別有順序關係(如教育程度:高中 < 大學 < 碩士)
為什麼對 Tree 有效:
- Tree 可以學到「>」「<」的關係
- 不會被順序誤導
陷阱:
# 在 Linear model 用 Label Encoding 會出事
# 例:顏色 [紅, 綠, 藍] → [0, 1, 2]
# 模型會以為「藍色 = 2 × 紅色」→ 錯誤!
Target Encoding
何時用:
- 高基數類別(> 100 個)
- 有目標變數(supervised learning)
- 用 Tree-based models(對 leakage 較不敏感)
原理:
# 用「該類別的平均目標值」替代類別
city_mean = train_df.groupby('city')['price'].mean()
train_df['city_encoded'] = train_df['city'].map(city_mean)
# 台北的平均房價 80 萬 → 台北 encode 成 80
# 高雄的平均房價 40 萬 → 高雄 encode 成 40
為什麼強大:
- 直接捕捉「類別 → 目標」的關係
- 降維(500 個城市 → 1 個數值特徵)
致命陷阱:Data Leakage
# ❌ 錯誤:用全部資料計算 mean
city_mean = df.groupby('city')['price'].mean()
df['city_encoded'] = df['city'].map(city_mean)
train, test = train_test_split(df)
# 問題:test set 的資訊洩漏到 encoding 裡了!
# ✅ 正確:只用 training set 計算
train, test = train_test_split(df)
city_mean = train.groupby('city')['price'].mean()
train['city_encoded'] = train['city'].map(city_mean)
test['city_encoded'] = test['city'].map(city_mean)
# 更好:用 Cross-Validation Target Encoding
from category_encoders import TargetEncoder
te = TargetEncoder()
te.fit(X_train, y_train)
X_train_encoded = te.transform(X_train)
X_test_encoded = te.transform(X_test)
決策框架:數值特徵處理
特徵分布?
├─ 長尾/右偏態(收入、房價、訂單金額)
│ └─ Log Transformation: np.log1p(x)
│
├─ 有大量異常值
│ ├─ 可以移除?(如明顯的資料錯誤)
│ │ └─ 是 → 移除
│ └─ 不能移除?
│ └─ RobustScaler 或 clip
│
├─ 接近正態分布
│ └─ StandardScaler
│
└─ 尺度差異很大(身高 cm vs 體重 kg)
├─ Neural Network?→ StandardScaler
├─ Tree models?→ 不需要 scaling
└─ 不確定?→ StandardScaler(最安全)
Log Transformation
何時用:
- 分布右偏態(長尾)
- 資料範圍跨度大(1-1000000)
為什麼有效:
# 原始:[10, 100, 1000, 10000, 100000]
# 跨度:10 - 100000(很大)
# 對 Linear model 很難學
# Log 後:[2.3, 4.6, 6.9, 9.2, 11.5]
# 跨度:2.3 - 11.5(小多了)
# 接近線性,模型好學
實戰案例:
# 房價預測
plt.hist(df['price']) # 右偏態,大部分 30-50 萬,少數 500 萬
# 不 transform:R² = 0.65
model = LinearRegression()
model.fit(X_train, y_train)
# Log transform:R² = 0.85
df['price_log'] = np.log1p(df['price'])
model.fit(X_train, df_train['price_log'])
StandardScaler vs MinMaxScaler
StandardScaler (Z-score):
# 轉換後:mean = 0, std = 1
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
何時用:
- 大多數情況(預設選這個)
- SVM, KNN, Neural Networks
- 對異常值較不敏感
MinMaxScaler:
# 轉換後:min = 0, max = 1
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
何時用:
- Neural Networks 的輸入層(特別是圖像)
- 知道明確的最大最小值範圍
- 需要固定範圍 [0, 1]
差異:
StandardScaler:
- 值可能超出 [-3, 3](異常值)
- 對異常值較穩健
MinMaxScaler:
- 值一定在 [0, 1]
- 對異常值敏感(一個極端值會壓縮其他值)
最致命的陷阱:Data Leakage
Data Leakage = 測試集資訊洩漏到訓練過程
這是最容易犯、但影響最嚴重的錯誤。
案例 1:在 split 前做 Scaling
# ❌ 錯誤
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 用全部資料 fit
X_train, X_test = train_test_split(X_scaled)
# 問題:test set 的 mean 和 std 影響了 scaling
# 結果:test set 表現虛高,部署後崩潰
# ✅ 正確
X_train, X_test = train_test_split(X)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 只用 train fit
X_test_scaled = scaler.transform(X_test) # test 用 train 的參數
案例 2:Feature Selection 用全部資料
# ❌ 錯誤
from sklearn.feature_selection import SelectKBest
selector = SelectKBest(k=10)
X_selected = selector.fit_transform(X, y) # 全部資料
X_train, X_test = train_test_split(X_selected)
# 問題:feature selection 看到 test set 了
# ✅ 正確
X_train, X_test, y_train, y_test = train_test_split(X, y)
selector = SelectKBest(k=10)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)
案例 3:時間序列用未來資訊
# ❌ 錯誤:移動平均包含未來資料
df['sales_ma7'] = df['sales'].rolling(7).mean()
# 問題:第 7 天的 MA 包含第 8-14 天的資料(未來資訊)
# ✅ 正確:shift 確保只用過去資料
df['sales_ma7'] = df['sales'].shift(1).rolling(7).mean()
小結
記住這些:
-
類別特徵處理決策:
- < 10 個:One-Hot
- 10-100 個:Tree 用 Label,Linear 用 One-Hot
-
100 個:Target Encoding(小心 leakage)
-
數值特徵處理決策:
- 長尾:Log transformation
- 異常值:RobustScaler
- 預設:StandardScaler
-
Data Leakage 是最大的坑:
- 永遠先 split,再做任何處理
- Test set 絕對不能影響 training
- 時間序列不能用未來資訊
-
Feature Engineering > 模型選擇:
- 好特徵 + 簡單模型 > 壞特徵 + 複雜模型
- 領域知識 > 自動化工具
Chapter 6: 常見模型的致命弱點 — 避坑指南
每個模型都有「隱藏的假設」,違反假設就會失效。這章整理各模型的致命弱點。
Linear Models (Linear Regression, Logistic Regression)
假設:特徵與目標是線性關係
致命弱點
1. 無法捕捉非線性
# 真實關係:y = x²
X = np.linspace(0, 10, 100).reshape(-1, 1)
y = X**2
model = LinearRegression()
model.fit(X, y)
# R² 很低,因為是線性模型硬擬合二次曲線
解法:
- 加入多項式特徵:
PolynomialFeatures(degree=2) - 換模型:Tree-based models
2. 對異常值敏感
# 一個極端值就能拉偏整條線
X = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 100] ← 最後一個是異常值
model = LinearRegression()
# 整條線被拉高,前面 4 個點的預測都變差
解法:
- 移除異常值
- 用 RobustScaler
- 換模型:Huber Regression(對異常值穩健)
3. 多重共線性
# 兩個特徵高度相關(如總房間數 vs 臥室數)
# 係數變得不穩定,難以解釋
解法:
- 移除相關特徵
- Ridge Regression (L2 regularization)
何時避開 Linear Models
- 特徵與目標明顯非線性(先畫 scatter plot 檢查)
- 有大量異常值
- 需要捕捉複雜的交互作用
Decision Trees
假設:資料可被逐步切割
致命弱點
1. 極易 Overfit
# 預設設定會長到每個葉子只有 1 個樣本
tree = DecisionTreeClassifier() # 沒限制深度
tree.fit(X_train, y_train)
print(f"Train: {tree.score(X_train, y_train):.3f}") # 1.000
print(f"Test: {tree.score(X_test, y_test):.3f}") # 0.650
# 完全記住訓練集,泛化能力差
解法:
- 限制深度:
max_depth=5 - 限制葉子樣本數:
min_samples_leaf=20 - 換 Random Forest(ensemble 降低 variance)
2. 對資料變動敏感
# 只改變一個樣本,整棵樹結構可能完全不同
# 導致預測不穩定
3. 無法 Extrapolate
# 訓練資料:房價 10-100 萬
# 測試資料:房價 150 萬
# Decision Tree 只會預測「訓練集看過的最大值」
# 無法預測超出訓練範圍的值
何時避開 Decision Trees
- 資料量小(< 1000 筆)→ 容易 overfit
- 需要預測訓練範圍外的值
- 需要穩定的預測(小變動不能影響太大)
Random Forest / XGBoost
假設:Ensemble 可以降低 variance
致命弱點
1. 訓練慢
# 100 棵樹,每棵深度 10
# 訓練時間可能是單棵樹的 100 倍
2. 模型大,部署成本高
# 100 棵完整的樹存下來
# 模型檔案可能幾百 MB
# 推論時需要走訪所有樹
3. 對高維稀疏資料效果差
# 文字資料(TF-IDF):10000 維,但 95% 是 0
# Tree 在稀疏資料中很難找到好的分割點
# Neural Networks 或 Linear Models 可能更好
4. 無法 Extrapolate
# 跟 Decision Tree 一樣的問題
# 訓練集房價 10-100 萬
# 預測 150 萬的房子會失敗
何時避開 Random Forest
- 需要毫秒級推論(每次預測都要走訪 100 棵樹)
- 記憶體有限(模型太大)
- 高維稀疏資料(文字、one-hot 後有幾千個特徵)
SVM
假設:資料可線性分割(或用 kernel trick)
致命弱點
1. 訓練時間 O(n²) 或更差
# 大資料集(> 10 萬筆)訓練不動
# n = 100,000 → n² = 10,000,000,000
2. 對特徵尺度極度敏感
# 沒做 scaling,SVM 基本上廢了
# 必須 StandardScaler 或 MinMaxScaler
3. 超參數調整困難
# kernel, C, gamma 互相影響
# 需要大量實驗找到好的組合
4. 機率輸出未校準
# svm.predict_proba() 的機率不準
# 需要額外做 Calibration
何時避開 SVM
- 資料量大(> 10 萬筆)
- 沒時間調參
- 需要可靠的機率估計
Neural Networks
假設:萬能逼近器(理論上能學任何函數)
致命弱點
1. 需要大量資料
# < 1000 筆:效果通常不如 Tree models
# 1000-10000 筆:可能持平
# > 10000 筆:才開始有優勢
2. 超參數地獄
# 需要調整:
# - 層數
# - 每層神經元數
# - Activation function
# - Learning rate
# - Batch size
# - Optimizer
# - Regularization (Dropout, L2)
# - ...
# 組合爆炸,調參很花時間
3. 訓練慢,需要 GPU
# 沒 GPU,訓練時間可能是天級別
# 有 GPU,成本增加
4. 黑盒,難解釋
# 金融、醫療領域需要可解釋性
# Neural Networks 很難說明「為什麼」
何時避開 Neural Networks
- 資料量小(< 1 萬筆)
- 需要模型可解釋性
- 沒有 GPU 資源
- 表格資料(Tree models 通常更好)
模型選擇決策樹
資料量?
├─ < 1000 筆
│ ├─ 需要可解釋?→ Linear Models
│ └─ 不需要?→ Random Forest (小的)
│
├─ 1k-100k
│ ├─ 表格資料?
│ │ └─ Random Forest / XGBoost
│ └─ 影像/文字/序列?
│ └─ Neural Networks
│
└─ > 100k
├─ 表格資料?→ XGBoost / LightGBM
└─ 影像/文字/序列?→ Neural Networks
需要可解釋性?
├─ 是 → Linear Models / Decision Tree
└─ 否 → 任何模型
訓練時間有限?
├─ 是 → LightGBM / Linear Models
└─ 否 → 任何模型
推論速度 < 10ms?
├─ 是 → Linear Models / Small Trees
└─ 否 → 任何模型
小結
記住這些:
-
Linear Models:
- 快速、可解釋
- 但無法捕捉非線性、對異常值敏感
-
Decision Trees:
- 極易 overfit
- 無法 extrapolate(預測範圍外的值)
-
Random Forest / XGBoost:
- 表格資料首選
- 但大、慢、無法 extrapolate
-
SVM:
- 大資料集訓練不動
- 對 scaling 敏感
-
Neural Networks:
- 需要大量資料
- 超參數多,難調
-
沒有銀彈:
- 根據資料量、時間、可解釋性需求選擇
- 從簡單模型開始,逐步升級
全文總結:7 個關鍵決策點
終於寫完了!讓我們回顧這篇超長筆記的核心。
1. 商業價值對齊
核心:先想清楚要解決什麼問題
- 模型指標(Accuracy, AUC)只是代理
- 商業指標(收入、成本、使用者留存)才是目標
- A/B test 是唯一的真理
- 最簡單能 work 的方案就是最好的方案
記住:不要為了技術而技術。
2. 評估指標選擇
核心:Accuracy 會騙人,要根據成本選指標
- 類別不平衡 → 不能用 Accuracy
- FP 代價高 → 優化 Precision(垃圾郵件)
- FN 代價高 → 優化 Recall(癌症篩檢)
- 極度不平衡 → 必須用 PR-AUC
記住:先檢查資料平衡度,再選指標。
3. EDA(資料探索)
核心:訓練前先看資料,10 分鐘省下 10 小時
- 檢查類別平衡(最容易忽略)
- 檢查特徵分布(長尾?異常值?)
- 檢查缺失值模式(隨機 vs 系統性)
- 檢查相關性(移除冗餘特徵)
記住:視覺化是最便宜的 debug 工具。
4. Overfitting vs Underfitting
核心:用 Learning Curve 診斷
- Underfitting:Train 和 Test 都差 → 增加複雜度
- Overfitting:Train 好,Test 差 → Regularization
- Regularization 是對抗 Overfit 的第一選擇
記住:不要只看單一數字,要看 Train vs Test。
5. Training vs Inference 加速
核心:兩者優化邏輯完全不同
Training 加速:
- FP16 混合精度(記憶體減半,速度提升 2-3x)
- 資料載入優化(num_workers, pin_memory)
Inference 加速:
- Quantization(模型大小減 4 倍)
- Knowledge Distillation(10 倍加速,保留 95% 效能)
- Batch Prediction(非即時場景省 70-90% 成本)
記住:Inference 成本是長期的,值得投資時間優化。
6. Feature Engineering
核心:何時用哪種方法
類別特徵:
- < 10 個 → One-Hot
- 10-100 個 → Tree 用 Label,Linear 用 One-Hot
-
100 個 → Target Encoding(小心 leakage)
數值特徵:
- 長尾 → Log transformation
- 異常值 → RobustScaler
- 預設 → StandardScaler
最大的坑:Data Leakage
- 永遠先 split,再做任何處理
記住:好特徵 > 複雜模型。
7. 模型選擇
核心:沒有銀彈,根據場景選擇
快速決策:
- < 1000 筆 → Linear Models / Small Tree
- 表格資料 → XGBoost / LightGBM
- 影像/文字 → Neural Networks
- 需要可解釋 → Linear / Decision Tree
- 需要快速推論 → Linear Models
記住:從簡單模型開始,逐步升級。
最後的話
這篇筆記整理了我這幾年踩過的坑。機器學習不是背公式、套模型,而是做決策:
- 何時用哪個指標?
- 為什麼模型會失效?
- 如何避開陷阱?
Vibe Coding 時代,Claude 幫你寫 code,但決策還是得靠你自己。
希望這些筆記能幫你少走一些彎路。如果有幫助,歡迎分享給其他人。
如果有任何問題或想討論的,歡迎留言交流!
延伸閱讀
- Python 資料結構深度解析:不只是背複雜度,而是知道什麼時候該用哪一個 — 同系列:具體工具層的決策,選對資料結構才能讓 AI 生成的程式碼不出錯
- Design Pattern 深度解析:不只是套模板,而是知道什麼時候不該用 — 同系列:程式設計決策框架,AI 生成的程式碼需要工程師的判斷力
- AI 自主研究實驗:讓 Agent 在你睡覺時跑 100 個實驗 — Vibe Coding 的極致:讓 AI 不只寫程式碼,還能自己設計與執行 ML 實驗