RAG System 完整指南:從原理到實踐
想讓你的 LLM 應用能回答特定領域問題、引用可靠來源、提供最新資訊?這篇文章帶你從零開始掌握 RAG 系統!你將學到:如何選擇技術組合(Chunking、Embedding、Vector DB)、三大查詢優化策略(Query Transformation、Hybrid Search、Reranking)、成本與效能權衡、以及如何用 RAGAS 評估系統品質。從 POC 到 Production,一篇搞定。
Intro:為什麼需要 RAG?
核心問題:LLM 的限制
大型語言模型(LLM)雖然強大,但有明確的限制:
- Knowledge Cutoff - 訓練資料有時間截止點,無法取得最新資訊
- Hallucination - 不確定時會編造事實
- Domain Knowledge 不足 - 對特定領域(企業內部、專業領域)知識有限
- 無法引用來源 - 難以追溯與驗證
核心洞察:LLM 很聰明,但它不知道「你的資料」
這些限制在實際應用中會造成嚴重問題。想像你在建立一個企業內部的知識庫問答系統,LLM 對你公司的產品、流程、規範一無所知。或者你想建立一個法律諮詢系統,但 LLM 的訓練資料在 2023 年就停止了,無法提供最新的法規資訊。
RAG 如何解決?
RAG 透過檢索外部知識庫,提供了解決方案:
- 即時存取最新資訊:更新知識庫即生效,無需重新訓練模型
- 可追溯的引用來源:每個答案都能標註來自哪個文件,提升信任度
- 降低 Hallucination:基於真實文件回答,而非憑空編造
- 快速更新知識:新增文件到知識庫即可,幾分鐘內生效
RAG 的核心概念很簡單:當用戶提問時,先從知識庫中「檢索」相關文件,再將這些文件連同問題一起送給 LLM「生成」答案。這樣 LLM 就能基於真實、最新、特定領域的資料來回答問題。
Trade-offs
RAG 不是銀彈,它用「系統複雜度」換取「知識新鮮度」:
- 增加 Latency:典型的 RAG 系統會增加 200-500ms 的延遲
- 依賴檢索品質:如果檢索不到相關文件,答案品質會大打折扣
- 系統複雜度提升:需要維護 Vector Database、Embedding Pipeline、監控檢索品質等
何時使用 RAG?
✅ 適合的場景:
- 企業知識庫(內部文件、SOP、產品資訊)
- 客服系統(FAQ、產品手冊、政策說明)
- 法律/醫療/金融(需要引用明確來源的專業領域)
- 需要最新資訊的應用(新聞、市場資訊、技術文件)
❌ 不適合的場景:
- 通用對話機器人(閒聊、創意生成)
- 簡單的常識問答(「天空為什麼是藍色的?」)
- 純創意生成任務(寫詩、編故事)
決策關鍵:你的應用是否需要最新、可追溯、特定領域的知識?如果答案是肯定的,RAG 就是你需要的解決方案。
Chapter 2: RAG System 架構

2.1 整體流程(High-Level View)
讓我們從最高層次理解 RAG 系統的工作流程:
這個流程看起來很簡單,但關鍵在於理解每個環節的作用:
- User Input:用戶的問題或查詢
- Embedding:將文字轉換成向量(數學表示),這是通用技術
- RAG System:核心差異所在!這是讓 LLM 能「存取外部知識」的關鍵
- Build Prompt:將檢索到的文件和問題組合成 LLM 的輸入
- Answer:LLM 基於文件生成的答案
核心洞察:RAG 的價值就在於那個檢索系統
其他步驟(Embedding、Build Prompt)都是標準技術,任何 LLM 應用都會用到。但 RAG System 才是讓你的 LLM 能夠回答特定領域問題、提供最新資訊、引用可靠來源的關鍵。
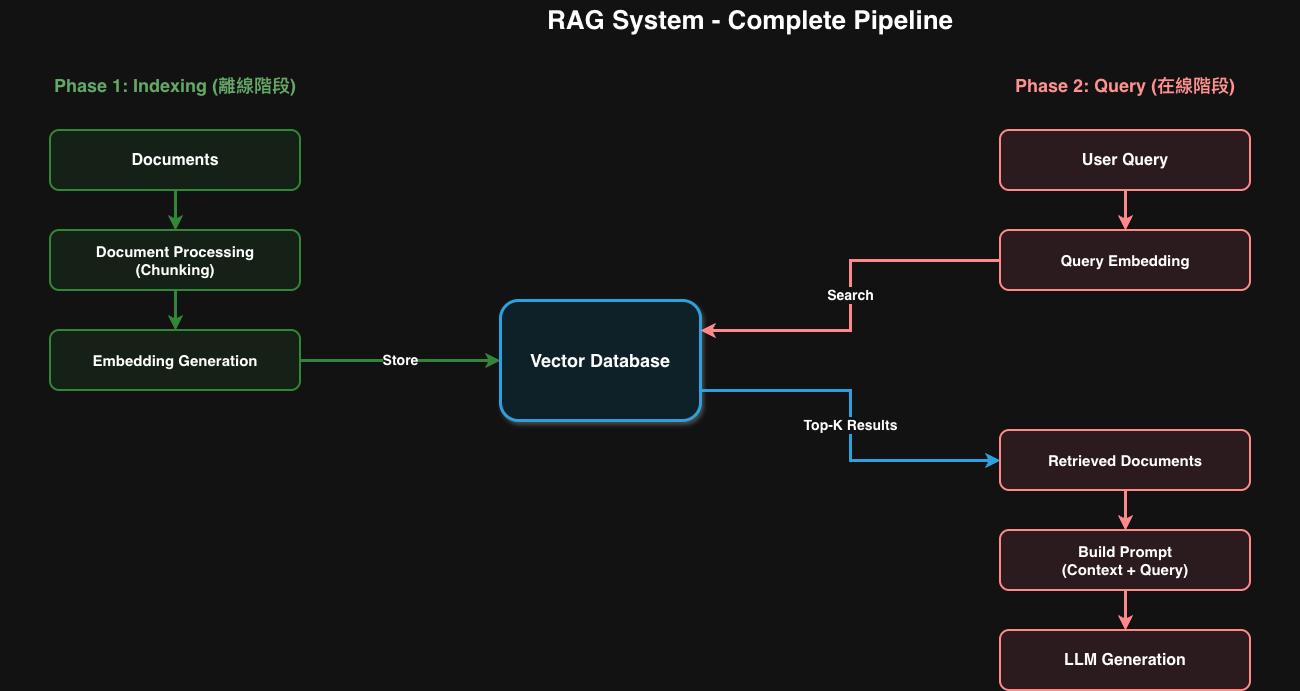
2.2 RAG System 內部:兩大階段
RAG System 並非單一步驟,而是包含兩大階段:
Phase 1: Indexing(離線階段)
做什麼:預先處理文件,建立向量索引
流程:
Documents → Document Processing → Embedding → Vector Database
關鍵組件:
- Document Processing - 切分文件(Chunking),因為完整文件通常太長
- Embedding Generation - 將文字片段轉成向量表示
- Vector Database - 儲存向量並建立索引,支援快速相似度搜尋
特點:
- 離線完成,不影響查詢速度
- 只需執行一次(或定期更新知識庫時執行)
- 為查詢階段做準備
這個階段就像在圖書館建立索引系統。你需要先把所有書籍分類、編號、建立目錄,之後讀者來查書時才能快速找到。
Phase 2: Query(在線階段)
做什麼:根據用戶問題,檢索相關文件
流程:
User Query → Query Embedding → Vector Search → Retrieved Documents
關鍵組件:
- Query Embedding - 將問題轉成向量(使用相同的 embedding model)
- Vector Search - 在 Vector DB 中尋找最相似的文件
- Retrieved Documents - 回傳 Top-K 最相關的文件片段
特點:
- 在線執行,每次查詢都會執行,會影響 latency
- 檢索品質決定最終答案品質
- 必須使用與 Indexing 階段相同的 embedding model
這個階段就像讀者拿著問題來圖書館查書。管理員(Vector Search)根據問題找出最相關的幾本書,讀者再根據這些書來獲得答案。
2.3 完整 RAG Pipeline
時間線說明:
- Phase 1 在系統啟動時執行(或知識庫更新時)
- Phase 2 每次用戶提問時執行
Vector Database 的角色: Vector Database 是連接兩個階段的橋樑。Indexing 階段將文件向量存入 Vector DB,Query 階段從 Vector DB 中檢索相關文件。這就是為什麼 Vector DB 在 RAG 系統中如此重要。
Embedding Model 的一致性: Indexing 和 Query 階段必須使用相同的 embedding model。如果你用 Model A 建立索引,卻用 Model B 來檢索,就像用中文建立目錄,卻用英文來查詢,結果會一團糟。
核心重點:
- RAG System 包含 Indexing 和 Query 兩大階段
- Indexing 在離線完成,Query 在在線執行
- Vector Database 是連接兩個階段的橋樑
- Embedding Model 的一致性至關重要
Chapter 3: Indexing 階段核心要點
Indexing 階段決定了知識庫的品質,但實務上不需要太複雜。讓我們聚焦在三個核心決策。
3.1 Document Processing - Chunking 策略
為什麼需要 Chunking?
- Embedding models 有 token limit(通常 512-8192 tokens)
- 較小的 chunks 提供更精確的檢索
- 完整文件通常包含多個主題,切分後能提升檢索準確度
核心策略(簡述 2 種):
1. Fixed-Size Chunking(最常用)
原理:固定大小切分(如 1000 tokens),並加入 overlap 避免切斷語義
範例:
原文:[0-1000 tokens] [1000-2000 tokens] [2000-3000 tokens]
切分:[0-1000] [800-1800] [1600-2600] ...
↑ 200 tokens overlap
優點:
- 簡單、快速
- 容易實作
- 適用大部分場景
參數建議:
- 一般場景:
chunk_size=1000, overlap=200 - 技術文件:
chunk_size=1500(保留完整程式碼區塊) - 短文本(FAQ):
chunk_size=500
2. Semantic Chunking(進階)
原理:根據語義邊界切分(如段落、章節)
優點:
- 保留語義完整性
- 每個 chunk 是完整的概念單元
缺點:
- 計算成本高
- 需要額外的 NLP 處理
- chunk 大小不一致
何時使用:
- 文件結構清晰(有明確的章節段落)
- 對語義完整性要求高
- 可接受額外的處理成本
實務建議: 大部分情況下,Fixed-Size Chunking 就足夠了。只有在文件結構非常重要的場景(如法律文件、技術規範)才需要 Semantic Chunking。
3.2 Embedding Model 選擇
核心原則: ⚠️ Indexing 與 Query 必須使用相同的 model
這點怎麼強調都不為過。如果你更換 embedding model,就需要重新建立整個索引。
常見選項:
| Model | 特點 | 適用場景 |
|---|---|---|
OpenAI text-embedding-3-small | 便宜、快速 | 一般應用、成本優先 |
OpenAI text-embedding-3-large | 高品質、貴 | 品質優先、企業應用 |
| BGE / Sentence-Transformers | 開源、免費 | 預算有限、自建服務 |
選擇考量:
- 品質 vs 成本:large model 品質更好但貴 10 倍
- 多語言支援:中文內容選擇支援中文的 model(如 BGE-M3)
- 是否需要自建:開源 model 可以自己部署,避免 API 依賴
實務建議:
- 從
text-embedding-3-small開始 - 如果檢索品質不足,再升級到
large - 企業內部資料考慮開源 model(資料隱私)
3.3 Vector Database 選擇
核心功能:
- 儲存向量(高維度陣列)
- 快速相似度搜尋(ANN - Approximate Nearest Neighbor)
- Metadata 過濾(按文件類型、時間等過濾)
常見選項:
| Vector DB | 特點 | 適用場景 |
|---|---|---|
| Pinecone | Managed service, production-ready | 不想維護、快速上線 |
| Weaviate | 開源、功能豐富、支援 hybrid search | 需要彈性、進階功能 |
| ChromaDB | 輕量級、易上手 | 開發測試、POC |
| Qdrant | 開源、效能好、Rust 實作 | 自建、效能優先 |
選擇關鍵:
- 規模:百萬級以下可用 ChromaDB,千萬級以上建議 Pinecone/Weaviate
- 預算:有預算用 managed service,沒預算用開源自建
- 維護能力:團隊小選 managed service,團隊大可自建
實務建議:
- POC 階段:ChromaDB(本地開發,零成本)
- Production 階段:Pinecone(免維護)或 Weaviate(彈性)
章節總結
Indexing 階段的 3 個核心決策:
- Chunking 策略 - 決定檢索粒度(推薦:Fixed-Size, 1000 tokens, 200 overlap)
- Embedding Model - 決定向量品質(推薦:text-embedding-3-small)
- Vector Database - 決定系統效能(推薦:POC 用 ChromaDB,Production 用 Pinecone)
這些決策會直接影響 Query 階段的檢索品質。記住:好的 Indexing 是成功的基礎,但不需要過度優化。從簡單的配置開始,根據實際效果再調整。
Chapter 4: Query 階段深入
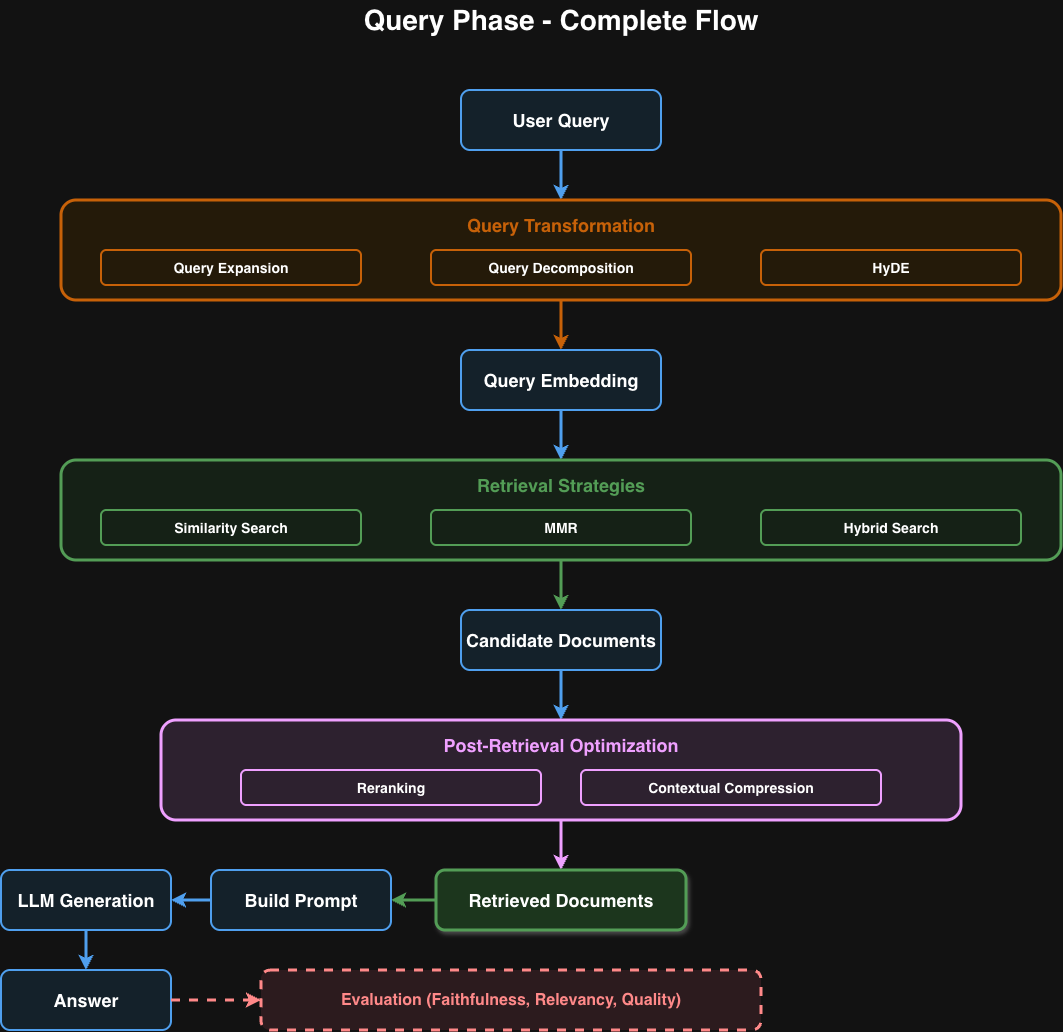
Query 階段是 RAG 系統的核心,決定了答案的品質。這個階段有三大優化機會點,讓我們逐一深入。
核心洞察:Query 階段的品質決定整個 RAG 系統的成敗。我們有三個主要的優化機會點,每個都能顯著提升檢索品質。
三大優化區塊:
- Query Transformation - 在檢索前優化查詢(讓問題更好找到答案)
- Retrieval Strategies - 選擇合適的檢索策略(找到最相關的文件)
- Post-Retrieval Optimization - 在檢索後精煉結果(過濾噪音、提升品質)
讓我們依序深入每個區塊。
4.2 Query Transformation(查詢優化)
為什麼需要 Query Transformation?
用戶的原始問題可能:
- 太簡短(「RAG 是什麼?」)→ 檢索詞不夠豐富
- 太複雜(包含多個子問題)→ 難以一次檢索完成
- 表達不精確(不是最佳的檢索詞)→ 找不到相關文件
核心概念:在將查詢轉成 embedding 之前,先對查詢本身進行優化。
4.2.1 Query Expansion(查詢擴展)
原理: 將簡短的查詢擴展成更詳細的描述,增加檢索的召回率。
範例:
原始查詢: "RAG 成本"
擴展後:
- "RAG 系統的實作成本"
- "Retrieval-Augmented Generation 的 API 費用"
- "RAG vs Fine-tuning 成本比較"
用 LLM 生成這些擴展查詢,然後分別檢索,最後合併結果。
適用場景:
- ✅ 簡短的查詢
- ✅ 需要提高召回率(寧可多找,不要漏找)
- ❌ 查詢已經很詳細(擴展反而引入噪音)
4.2.2 Query Decomposition(查詢拆解)
原理: 將複雜查詢拆解成多個子問題,分別檢索每個子問題,最後整合所有結果。
範例:
原始查詢: "比較 RAG 和 Fine-tuning 的成本、效果和適用場景"
拆解成:
1. "RAG 的成本是多少?"
2. "Fine-tuning 的成本是多少?"
3. "RAG 的效果如何?"
4. "Fine-tuning 的效果如何?"
5. "RAG 適合什麼場景?"
6. "Fine-tuning 適合什麼場景?"
為什麼有效? 複雜問題通常包含多個面向,單一檢索可能只找到部分答案。拆解後分別檢索,能確保每個面向都有相關文件。
核心概念(LangChain):
from langchain.chains import LLMChain
# 1. 用 LLM 拆解問題
sub_questions = decompose_query(complex_query) # 得到多個子問題
# 2. 分別檢索每個子問題
for sub_q in sub_questions:
docs = retriever.get_relevant_documents(sub_q)
適用場景:
- ✅ 複雜的多部分問題
- ✅ 需要多角度資訊
- ❌ 簡單的單一問題(拆解反而浪費)
4.2.3 HyDE (Hypothetical Document Embeddings)
原理: 不直接檢索問題,而是先讓 LLM 生成「假設性的答案」,用這個假設性答案去檢索。
為什麼這樣做? 基於一個洞察:答案和文件在 embedding space 中更接近。
想像一下:
- 問題:「RAG 如何減少 hallucination?」(抽象、簡短)
- 答案/文件:「RAG 透過檢索外部文件來減少 hallucination。當 LLM 需要回答問題時,它會先從知識庫中找到相關文件…」(具體、詳細)
答案的描述方式更接近文件的寫作風格,所以用答案去檢索會比用問題更準確。
範例:
原始查詢: "RAG 如何減少 hallucination?"
HyDE 生成假設性答案:
"RAG 透過檢索外部文件來減少 hallucination。當 LLM 需要回答問題時,
它會先從知識庫中找到相關文件,然後基於這些真實文件來生成答案,
而不是依賴訓練時的記憶。這確保了答案有事實依據..."
→ 用這段假設性答案的 embedding 去檢索
核心流程:
# 1. 用 LLM 生成假設性答案
hypothetical_answer = llm.generate_hypothetical_answer(query)
# 2. 用假設性答案來檢索(而非原始問題)
docs = vectorstore.similarity_search(hypothetical_answer, k=5)
適用場景:
- ✅ 抽象問題
- ✅ 文件內容偏長且描述性
- ❌ 需要精確關鍵字匹配(如「產品 X 的價格」)
- ❌ 極低 latency 要求(需要額外 LLM call,增加 200-500ms)
Trade-offs:
- ✅ 可能提升檢索品質
- ❌ 增加 latency
- ❌ 增加成本
- ❌ 假設性答案可能偏離實際需求
4.3 Retrieval Strategies(檢索策略)
這是 Query 階段的核心,決定能否找到相關文件。
Strategy 1: Similarity Search(基礎)
原理:
- 計算 query vector 與所有文件 vectors 的相似度
- 常用:Cosine Similarity(餘弦相似度)
- 回傳 Top-K 最相似的文件
公式:
Similarity = cos(θ) = (A · B) / (||A|| × ||B||)
優點:
- 簡單、快速
- 適合大部分場景
- 所有 Vector DB 都支援
缺點:
- 可能回傳過於相似的文件(缺乏多樣性)
- 純語義匹配,可能忽略關鍵字
範例:
docs = vectorstore.similarity_search(
query="什麼是 RAG?",
k=5
)
何時使用:
- ✅ 簡單查詢
- ✅ 初版 RAG 系統
- ✅ 對多樣性沒有特別要求
Strategy 2: MMR - Maximal Marginal Relevance(多樣性)
原理: 平衡相關性(relevance)與多樣性(diversity),避免回傳太多相似的文件。
為什麼需要? Similarity Search 可能回傳 5 篇都在講同一件事的文件,這樣就浪費了 context window。MMR 會確保檢索結果有更好的涵蓋面。
演算法:
1. 先找出最相關的文件(最高相似度)
2. 接下來每次選擇:
- 與 query 相似 (relevance)
- 但與已選文件不同 (diversity)
3. 平衡兩者,選出 Top-K
參數:
lambda_mult=0:最大化多樣性(可能犧牲相關性)lambda_mult=1:最大化相關性(退化成 Similarity Search)lambda_mult=0.5:平衡(推薦)
範例:
docs = vectorstore.max_marginal_relevance_search(
query="RAG 的應用場景",
k=5,
fetch_k=20, # 先取 20 個候選
lambda_mult=0.5 # 平衡相關性與多樣性
)
適用場景:
- ✅ 開放性問題(「介紹一下 RAG」)
- ✅ 需要多角度資訊
- ❌ 精確查詢(「XXX 的價格是多少?」)
Strategy 3: Hybrid Search(最推薦)⭐
原理: 結合 Vector Search(語義相似)與 BM25(關鍵字匹配),融合兩種檢索結果。
為什麼 Hybrid 更好?
Vector Search 的限制:
- 語義相似但可能忽略關鍵字
- 例:查詢「GPT-4」,可能找到「LLM」的文件但沒有明確提到 GPT-4
BM25 的限制:
- 只匹配關鍵字,忽略語義
- 例:查詢「如何優化效能」,無法匹配「提升速度」
Hybrid Search 的優勢:
- 結合兩者優點
- 既能語義匹配,又能確保關鍵字存在
- 實務中效果通常最好
關鍵套件(LangChain):
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# 組合 Vector Search + BM25
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.5, 0.5] # Vector:BM25 權重比
)
docs = ensemble_retriever.get_relevant_documents(query)
權重調整:
[0.7, 0.3]:更重視語義(適合描述性查詢)[0.5, 0.5]:平衡(推薦預設)[0.3, 0.7]:更重視關鍵字(適合精確查詢)
何時使用:
- ✅ Production 環境(推薦預設使用)
- ✅ 需要平衡語義與關鍵字
- ✅ 查詢包含專有名詞(人名、產品名、技術名)
實務建議: Hybrid Search 是 CP 值最高的優化。如果只能加一個優化技術,就選 Hybrid Search。
4.4 Post-Retrieval Optimization(檢索後優化)
核心概念: 從 Vector Database 檢索到候選文件後,我們還有最後一次機會來精煉結果。這個階段有兩個主要技術:Reranking 和 Contextual Compression。
4.4.1 Reranking(重新排序)
為什麼需要 Reranking?
檢索階段的問題:
- Vector search 基於 embedding 的相似度
- 但 embedding 不一定完美反映「相關性」
- 可能相似但不相關,或相關但不夠相似
Reranking 的作用: 用更精確的模型重新評分,從候選文件中挑出最相關的。
兩階段檢索架構:
Stage 1: Retrieval (快速, 粗篩)
Vector/Hybrid Search → 10-20 候選文件
↓
Stage 2: Reranking (精確, 細選)
Cross-Encoder 重新評分 → Top 3-5 最終文件
為什麼是兩階段?
-
Bi-Encoder(用於 Vector Search):快但不夠精確
- 分別對 query 和 document 編碼,然後計算相似度
- 可以預先計算所有文件的 embedding,檢索時只需計算 query embedding
-
Cross-Encoder(用於 Reranking):精確但慢
- 同時處理 query 和 document,直接輸出相關性分數
- 無法預先計算,每次都需要重新計算
組合策略:先用快的粗篩(Bi-Encoder),再用慢的精選(Cross-Encoder)。
常用工具:
- Cohere Rerank API(最簡單)
- Jina Reranker
- Cross-Encoder models (Hugging Face)
關鍵套件(LangChain + Cohere):
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
# 組合:Base Retriever + Reranker
compression_retriever = ContextualCompressionRetriever(
base_compressor=CohereRerank(top_n=3), # 從候選中挑最好的 3 個
base_retriever=vectorstore.as_retriever(k=20) # 先取 20 個候選
)
效果:
- 顯著提升檢索準確度(通常 10-20% 提升)
- 減少不相關文件進入 LLM context
Trade-offs:
- ✅ 提升品質
- ❌ 增加 latency(額外 API call,約 200-300ms)
- ❌ 增加成本(Reranking API 費用,約 $0.002/query)
何時使用:
- ✅ 準確度要求高的場景
- ✅ 可接受額外 latency
- ❌ 極低 latency 要求(< 500ms)
4.4.2 Contextual Compression(上下文壓縮)
為什麼需要 Compression?
問題:
- 檢索到的文件可能很長(1000+ tokens)
- 但只有部分內容與問題相關
- 送太多不相關內容給 LLM 會:
- 增加 token 成本
- 增加噪音
- 降低答案品質(Lost in the middle 問題)
Contextual Compression 的作用: 從每個文件中只提取與查詢相關的部分,移除不相關的內容。
流程:
Retrieved Document (1000 tokens)
↓
Contextual Compression
↓
Compressed Document (200 tokens, 只留相關部分)
實作方式 1:Extractive (抽取式) 用 LLM 或模型找出最相關的句子/段落,只保留這些部分。
實作方式 2:Abstractive (摘要式) 用 LLM 生成簡短的摘要,保留關鍵資訊。
關鍵套件(LangChain):
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.retrievers import ContextualCompressionRetriever
# 用 LLM 提取文件中與查詢相關的部分
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
效果:
- 減少 token 成本(通常 50-70% 減少)
- 提升答案品質(減少噪音)
- 更好地利用 context window
Trade-offs:
- ✅ 降低成本
- ✅ 提升品質
- ❌ 增加 latency(需要額外處理)
- ❌ 可能遺失重要資訊
何時使用:
- ✅ 文件很長(> 500 tokens per doc)
- ✅ Context window 有限
- ✅ 需要控制成本
- ❌ 文件已經很短且精確
4.4.3 組合使用:Reranking + Compression
最佳實踐: 將兩種技術組合使用,達到最佳效果。
流程:
Retrieval → 20 候選文件
↓
Reranking → Top 5 文件
↓
Contextual Compression → 壓縮每個文件
↓
Final Documents → 送給 LLM
Pipeline 組合(LangChain):
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
# 將多個優化技術串接成 Pipeline
compressor_pipeline = DocumentCompressorPipeline(
transformers=[
CohereRerank(top_n=5), # Step 1: Reranking
LLMChainExtractor.from_llm(llm) # Step 2: Compression
]
)
這樣既保證了文件的相關性(Reranking),又減少了噪音和成本(Compression)。
4.4.4 Top-K 數量的權衡
關鍵問題:應該檢索多少個文件?
太少(Top-3):
- ❌ 可能遺漏重要資訊
- ❌ 檢索失敗的風險高
- ✅ Latency 低
- ✅ 成本低
太多(Top-10+):
- ✅ 資訊完整
- ❌ 增加 LLM token 成本
- ❌ 可能引入噪音(不相關文件)
- ❌ LLM 可能忽略後面的文件(Lost in the middle)
實務建議:
- 沒有 Reranking:Top-5
- 有 Reranking:先取 Top-20,Rerank 後取 Top-3 到 Top-5
- 需要完整資訊:Top-10(但要注意 context limit)
動態調整: 根據檢索分數決定:
# 只取 score > threshold 的文件
docs_with_scores = vectorstore.similarity_search_with_score(query, k=10)
relevant_docs = [doc for doc, score in docs_with_scores if score > 0.7]
4.5 Build Prompt - 組裝 Context
目標:將檢索到的文件與用戶問題組合成 LLM prompt
Prompt 結構範例:
請根據以下文件回答問題。重要:只根據文件內容回答,無法回答時請說明。
[Document 1] {doc1_content}
[Document 2] {doc2_content}
問題:{user_query}
請回答並標註來源。
關鍵設計原則:
- ⚠️ 明確指示「只根據文件回答」(減少 hallucination)
- ⚠️ 要求引用來源(提升可追溯性)
- ⚠️ 允許說「不知道」(避免編造答案)
- 為文件加上編號(方便引用)
為什麼這些原則重要?
- 「只根據文件回答」:LLM 預設會使用訓練時的知識。明確指示能大幅降低 hallucination。
- 「要求引用來源」:讓 LLM 標註資訊來自哪個文件,使用者能追溯驗證。
- 「允許說不知道」:比編造答案好。使用者寧可知道系統不確定,也不要被錯誤資訊誤導。
4.6 LLM Generation 與 Citations
最後一步:LLM 基於 context 生成答案
關鍵要求:
- 基於 context:不要使用訓練時的知識
- 引用來源:標註資訊來自哪個文件
- 承認不足:如果 context 不夠,說「資料不足」
Citation 格式:
答案:RAG 是 Retrieval-Augmented Generation 的縮寫 [Doc 1]。
它結合了檢索系統與生成模型 [Doc 2]。
來源:
- [Doc 1]: technical_guide.pdf, Page 3
- [Doc 2]: rag_paper.pdf, Abstract
關鍵套件(LangChain):
from langchain.chains import RetrievalQAWithSourcesChain
# 建立帶有來源引用的 QA Chain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True # 回傳來源文件
)
result = qa_chain({"question": query})
# result['answer'] - 答案
# result['sources'] - 來源標註
這樣使用者不僅得到答案,還能看到答案的來源,大幅提升信任度。
4.7 Evaluation(評估 RAG 系統品質)
為什麼需要 Evaluation?
RAG 系統是複雜的 pipeline,需要確保:
- 檢索到的文件是相關的(Retrieval Quality)
- 生成的答案是正確的(Generation Quality)
- 答案基於文件而非編造(Faithfulness)
三大評估維度:
4.7.1 Faithfulness(忠實度)
定義: 答案是否忠實於檢索到的文件?有沒有編造資訊?
評估問題:
- 答案中的每個陳述是否都能在文件中找到支持?
- 有沒有超出文件範圍的資訊?
為什麼重要: 這是 RAG 的核心價值 - 我們不希望 LLM 使用訓練時的知識,而是只基於檢索到的文件回答。
評估方式: 用 LLM 評估答案中的每個陳述是否能在文件中找到支持。
# 評估 Faithfulness:答案是否忠實於文件
score = evaluate_faithfulness(
context=retrieved_docs,
answer=generated_answer
)
# 評分: 1-3 (1=編造, 3=完全基於文件)
常見問題:
- LLM 加入了自己的知識
- 過度推論
- 混合多個文件的資訊時出錯
4.7.2 Relevancy(相關性)
定義: 檢索到的文件是否與問題相關?答案是否真的回答了問題?
評估層次:
1. Answer Relevancy(答案相關性)
- 答案是否真的回答了問題?
- 有沒有答非所問?
2. Context Relevancy(上下文相關性)
- 檢索到的文件是否與問題相關?
- 有多少文件是真正有用的?
評估方法:
# Context Relevancy Score
relevant_docs = 0
for doc in retrieved_docs:
if is_relevant_to_query(doc, query): # 可用 LLM 評估
relevant_docs += 1
context_relevancy = relevant_docs / len(retrieved_docs)
理想目標:
- Answer Relevancy: 100%(答案必須回答問題)
- Context Relevancy: > 80%(大部分文件都相關)
4.7.3 Quality(整體品質)
定義: 答案的整體品質如何?
評估面向:
1. Correctness(正確性)
- 答案在事實上是否正確?
- 需要人工標註或與 ground truth 比較
2. Completeness(完整性)
- 答案是否完整回答了問題?
- 有沒有遺漏重要資訊?
3. Clarity(清晰度)
- 答案是否清楚易懂?
- 結構是否良好?
評估方式: 綜合評估答案的正確性、完整性和清晰度。
# 整體品質評分 (1-5)
quality_score = evaluate_quality(
question=query,
answer=answer,
criteria=["correctness", "completeness", "clarity"]
)
4.7.4 實務評估工具
RAGAS (RAG Assessment)
業界標準的 RAG 評估框架:
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_relevancy
# 準備評估資料
evaluation_data = {
"question": [query1, query2, ...],
"answer": [answer1, answer2, ...],
"contexts": [[doc1, doc2], ...],
}
# 執行評估
result = evaluate(evaluation_data, metrics=[...])
# 輸出: {"faithfulness": 0.92, "answer_relevancy": 0.88, ...}
輸出範例:
{
"faithfulness": 0.92, # 答案忠實於文件
"answer_relevancy": 0.88, # 答案回答了問題
"context_relevancy": 0.75, # 文件與問題相關
}
RAGAS 會自動用 LLM 評估這些指標,非常方便。
4.7.5 持續監控與優化
建立評估 Pipeline:
Production RAG System
↓
定期抽樣查詢
↓
自動評估 (RAGAS)
↓
低分案例標記
↓
人工檢視
↓
系統優化
優化方向:
- Faithfulness 低 → 改進 prompt(強調只用文件回答)
- Context Relevancy 低 → 改進檢索策略(Reranking, Query Transformation)
- Answer Relevancy 低 → 改進生成 prompt
核心洞察:無法衡量就無法改進。建立評估機制是優化 RAG 系統的第一步。
章節總結
Query 階段的完整架構:
三大優化區塊:
1. Query Transformation (Query Expansion/Decomposition/HyDE)
2. Retrieval Strategies (Similarity/MMR/Hybrid Search)
3. Post-Retrieval Optimization (Reranking/Contextual Compression)
最終評估:
- Faithfulness (忠實度)
- Relevancy (相關性)
- Quality (整體品質)
最佳實踐組合(Production 推薦):
User Query
→ [可選] Query Transformation
→ Query Embedding
→ Hybrid Search (Vector + BM25) → Top-20 候選
→ Reranking → Top-5
→ [可選] Contextual Compression
→ Build Prompt with Citations
→ LLM Generation
→ Evaluation (RAGAS)
核心洞察:Query 階段有三個主要的優化機會點。根據你的場景、預算和 latency 要求,選擇合適的優化技術組合。記住:檢索品質決定答案品質,投資在檢索優化上的回報通常比優化 prompt 更高。
下一章預告:實務考量與優化建議
Chapter 5: 實務考量與優化建議
技術細節固然重要,但實務上還需要考慮成本、速度和品質的權衡。這章提供實戰經驗和決策建議。
5.1 成本估算
RAG 系統的主要成本來源:
Indexing 階段(一次性):
- Embedding API:文件數量 × 平均 tokens × embedding 單價
- 例:10,000 文件 × 500 tokens × $0.0001/1K tokens = $0.50
很便宜,對吧?Indexing 通常不是成本瓶頸。
Query 階段(每次查詢):
- Query Embedding:~$0.00001 per query(幾乎可忽略)
- LLM Generation:平均輸入 tokens × 單價
- 例:5 docs × 200 tokens + 50 query tokens = 1050 tokens → ~$0.003
- Reranking (可選):~$0.002 per query
- Vector DB:儲存 + 查詢費用(依據服務商)
月成本估算範例:
10,000 queries/month:
- Embedding: $0.10
- LLM Generation: $30
- Reranking (可選): $20
- Vector DB: $10-50 (依規模)
---
總計: $40-100/month
成本分析:
- LLM Generation 是最大成本(通常佔 60-80%)
- Reranking 是第二大成本(若啟用)
- Vector DB 成本取決於資料量和服務商
優化建議:
- 使用較小的 embedding model(如
text-embedding-3-small) - 減少每次檢索的文件數量(Top-K)
- Cache 常見問題的結果(大幅降低重複查詢成本)
5.2 Latency 分析
典型 RAG Pipeline 的 Latency Breakdown:
Query Embedding: 50-100ms
Vector Search: 50-150ms
Reranking (可選): 200-300ms
LLM Generation: 500-2000ms (依 model 大小)
---
Total: 600ms - 2.5s
瓶頸識別:
- LLM Generation 是最大瓶頸(通常佔 70-80%)
- Reranking 是第二大瓶頸(若啟用)
- Retrieval 本身很快(< 200ms)
優化策略:
1. 降低 LLM Latency
這是最重要的優化方向:
- 使用較小的 model:GPT-4 → GPT-3.5(快 2-3 倍)或 Claude Haiku(更快)
- 使用 Streaming:逐字輸出,使用者能立刻看到回應,體感速度大幅提升
- 減少輸入 tokens:使用 Contextual Compression,減少送給 LLM 的文件長度
2. 降低 Retrieval Latency
雖然不是主要瓶頸,但也能優化:
- 減少 Top-K 數量(20 → 10)
- 使用更快的 Vector DB
- 移除 Reranking(若 latency 要求極高)
3. Async & Parallel
某些步驟可以並行處理:
- Query Embedding 和其他準備工作可並行
- 多個檢索請求可並行(Multi-query Retrieval)
Latency 要求參考:
- Interactive Chat:< 2s(可接受 Reranking)
- Q&A System:< 1s(考慮移除 Reranking)
- Real-time Search:< 500ms(只用基礎 Retrieval + Streaming)
5.3 技術選擇建議
根據不同需求選擇技術組合。
配置 1:Minimal(快速驗證)
適用:POC、個人專案、低流量
Chunking: Fixed-size (1000 tokens, 200 overlap)
Embedding: OpenAI text-embedding-3-small
Vector DB: ChromaDB / Pinecone Free Tier
Retrieval: Similarity Search (Top-5)
Reranking: ✗
Query Transformation: ✗
---
Latency: ~600ms
成本: ~$10-20/month (1000 queries)
這是最簡單的配置,足以驗證 RAG 是否適合你的場景。
配置 2:Standard(Production 起手式)
適用:中型應用、準確度有要求
Chunking: Fixed-size (1000 tokens, 200 overlap)
Embedding: OpenAI text-embedding-3-large
Vector DB: Pinecone / Weaviate
Retrieval: Hybrid Search (Vector + BM25, Top-10)
Reranking: ✗ (初期可省略)
Query Transformation: ✗ (初期可省略)
---
Latency: ~800ms
成本: ~$50-80/month (5000 queries)
加入 Hybrid Search 能顯著提升品質,是 Production 的推薦起手式。
配置 3:Premium(高品質要求)
適用:企業級應用、準確度優先
Chunking: Semantic Chunking
Embedding: OpenAI text-embedding-3-large
Vector DB: Pinecone / Weaviate (Production tier)
Retrieval: Hybrid Search (Top-20 候選)
Reranking: ✓ Cohere Rerank (Top-5)
Query Transformation: ✓ Query Expansion / HyDE
Contextual Compression: ✓
Evaluation: ✓ RAGAS
---
Latency: ~1.5s
成本: ~$150-300/month (10000 queries)
這是完整配置,適合對品質有高要求的企業應用。
選擇原則:
- 從 Minimal 開始,驗證需求
- 根據品質評估結果,逐步升級
- 優先加入 Hybrid Search(CP 值最高)
- Reranking 和 Query Transformation 視需求加入
5.4 常見問題與解決方案
實務中會遇到各種問題,這裡整理最常見的四個問題和解決方案。
問題 1:檢索品質差,找不到相關文件
症狀:
- 明明知識庫有相關資訊,卻檢索不到
- 檢索到的文件與問題不相關
- 答案品質差
可能原因:
- Chunking 策略不當(太大或太小)
- 只用 Vector Search(忽略關鍵字)
- Embedding model 不適合你的領域
解決方案:
- 檢查 chunk size(試試 500, 1000, 1500)
- 優先試試 Hybrid Search(效果立竿見影)
- 考慮換 embedding model(多語言內容 → BGE-M3)
- 加入 Query Expansion(擴展查詢詞)
診斷方法: 用 RAGAS 的 context_relevancy 指標評估。如果低於 0.7,說明檢索品質確實有問題。
問題 2:答案不準確,有 Hallucination
症狀:
- 答案包含知識庫中沒有的資訊
- LLM 編造事實
- 引用不存在的來源
可能原因:
- 檢索到的文件不夠相關(根本原因)
- Prompt 沒有限制 LLM 只用文件
- 文件太多太雜(噪音過多)
解決方案:
- 在 prompt 中明確要求「只根據文件回答」
- 加入 Reranking(提升文件相關性)
- 減少 Top-K 數量(降低噪音)
- 要求 LLM 引用來源(提升可追溯性)
- 使用 RAGAS 評估 Faithfulness
Prompt 範例:
重要:請只根據以下文件回答問題。
如果文件中沒有相關資訊,請明確說「文件中沒有提供這個資訊」。
不要使用你的訓練知識,不要編造答案。
問題 3:Latency 太高,用戶體驗差
症狀:
- 回應時間超過 2 秒
- 使用者抱怨速度慢
- 需要優化效能
可能原因:
- LLM Generation 太慢(主要原因)
- 使用了 Reranking(增加 200-300ms)
- 檢索文件太多
解決方案:
- 使用 Streaming(立即開始輸出,大幅提升體感速度)
- 換更快的 LLM(GPT-4 → GPT-3.5 或 Claude Haiku)
- 移除 Reranking(若品質可接受)
- 減少 Top-K(5 → 3)
- 使用 Contextual Compression(減少 LLM 輸入)
優先順序: Streaming > 換 LLM > 減少 Top-K > 移除 Reranking
問題 4:成本太高
症狀:
- 月費用超出預算
- 每次查詢成本過高
- 需要降低成本
可能原因:
- 使用昂貴的 embedding model
- 每次檢索文件太多
- 使用 GPT-4(成本是 GPT-3.5 的 10-20 倍)
- 沒有 Cache 重複查詢
解決方案:
- 換較便宜的 embedding(large → small)
- 減少 Top-K 數量
- 實作 Cache(常見問題直接回傳,大幅節省成本)
- 換較便宜的 LLM(或混合使用:簡單問題用便宜 model)
- 移除 Reranking API
Cache 策略:
# 簡單的 Cache 實作
cache = {}
def rag_with_cache(query):
if query in cache:
return cache[query] # 直接回傳,省下所有成本
result = rag_pipeline(query)
cache[query] = result
return result
常見問題的重複率可能高達 30-50%,Cache 能大幅降低成本。
章節總結
實務上的權衡三角:
品質
/\
/ \
/ \
/______\
成本 速度
你不可能同時最大化三者,必須根據場景選擇。
核心建議:
- 從簡單開始:先用 Minimal 配置驗證需求
- 優先加 Hybrid Search:CP 值最高的優化
- 根據評估結果優化:用 RAGAS 找出瓶頸
- 不要過度優化:夠用就好,避免過早優化
升級路徑:
Similarity Search
↓ (品質不足?)
+ Hybrid Search
↓ (還是不夠?)
+ Reranking
↓ (複雜問題?)
+ Query Transformation
最重要的建議:在加入複雜技術前,先確保基礎做對了:好的 Chunking 策略、清楚的 Prompt、適合的 Embedding Model。這些基礎比任何進階技術都重要。
補充:Agentic RAG 簡介
在結束前,讓我們快速了解 RAG 的進階版本:Agentic RAG。
什麼是 Agentic RAG?
Agentic RAG 是 RAG 的進階版本,引入了 Agent 的概念,讓系統能夠自主決策和行動。
核心差異:
| 特性 | 傳統 RAG | Agentic RAG |
|---|---|---|
| 流程 | 固定流程(Query → Retrieval → Generation) | 動態決策流程 |
| 檢索次數 | 一次檢索 | 可多次檢索 |
| 決策能力 | 無,按照預設流程執行 | 有,Agent 自主判斷 |
| 工具使用 | 只能檢索 | 可使用多種工具 |
| 複雜度 | 簡單 | 複雜 |
Agentic RAG 的工作方式
傳統 RAG:
User Query → Retrieval → Generation → Answer
每個查詢都走相同的流程,簡單但缺乏彈性。
Agentic RAG:
User Query
↓
Agent 分析問題
↓
決策: 需要檢索什麼?檢索幾次?
↓
第一次 Retrieval
↓
Agent 判斷: 資訊夠嗎?
├─ 夠 → Generation → Answer
└─ 不夠 → 調整查詢 → 第二次 Retrieval → ...
Agent 會根據情況動態調整,像一個真正的研究助手。
關鍵能力:
-
ReAct Pattern(Reasoning + Acting)
- Agent 會思考「我現在需要什麼資訊?」
- 決定下一步行動(檢索、計算、呼叫 API 等)
-
Multi-hop Retrieval(多跳檢索)
- 根據第一次檢索結果,決定是否需要第二次檢索
- 例:先查「什麼是 RAG?」→ 再查「RAG 的成本分析」
-
Tool Use(工具使用)
- 不只檢索,還能呼叫計算器、搜尋引擎、資料庫等
- 例:查詢產品價格 → 呼叫價格 API → 計算總成本
範例:對比
問題:「GPT-4 和 Claude 3.5 Sonnet 哪個比較便宜?」
傳統 RAG:
→ 檢索「GPT-4 Claude 價格比較」
→ 找到相關文件
→ 生成答案
問題:如果文件中沒有直接比較,可能答不出來。
Agentic RAG:
→ Agent 分析:需要分別查兩個模型的價格
→ 第一次檢索:「GPT-4 價格」
→ 第二次檢索:「Claude 3.5 Sonnet 價格」
→ Agent 判斷:需要計算比較
→ 使用計算器工具
→ 生成答案:「GPT-4 input 是 $X,Claude 是 $Y,Claude 便宜 Z%」
Agentic RAG 能分解問題、多次檢索、使用工具,更接近人類的研究方式。
何時使用 Agentic RAG?
✅ 適合:
- 複雜的多步驟問題
- 需要多次檢索才能回答
- 需要結合多種資料來源
- 需要推理和決策的場景
❌ 不適合:
- 簡單的單次檢索問題
- 對 latency 要求極高(Agentic RAG 較慢)
- 需要可預測的固定流程
- 預算有限(成本較高,多次 LLM 呼叫)
實務建議
選擇原則:
問題簡單、直接?
→ 傳統 RAG(快速、便宜、可預測)
問題複雜、需要多步驟?
→ Agentic RAG(彈性、智能、但較慢較貴)
常見架構:
- LangGraph:最流行的 Agentic workflow 框架,支援複雜的狀態管理和循環
- LangChain Agent:快速建立簡單 Agent,適合入門
- AutoGPT / BabyAGI:自主任務規劃,適合研究
核心洞察:Agentic RAG 是 RAG 的自然演進,但不是所有場景都需要。從傳統 RAG 開始,當遇到單次檢索無法解決的複雜問題時,再考慮升級到 Agentic RAG。
全文總結
我們從頭到尾走過了 RAG 系統的完整架構:
核心概念
- RAG = Retrieval + Generation,讓 LLM 能存取外部知識
- 兩大階段:Indexing(離線)+ Query(在線)
- 關鍵價值:最新資訊、可追溯來源、特定領域知識
關鍵技術
Indexing 階段:
- Chunking(推薦 Fixed-size, 1000 tokens, 200 overlap)
- Embedding(推薦 text-embedding-3-small)
- Vector Database(推薦 ChromaDB/Pinecone)
Query 階段(三大優化區塊):
- Query Transformation(Expansion/Decomposition/HyDE)
- Retrieval Strategies(Similarity/MMR/Hybrid Search ⭐)
- Post-Retrieval Optimization(Reranking/Compression)
Evaluation:
- Faithfulness(忠實度)
- Relevancy(相關性)
- Quality(整體品質)
- 工具:RAGAS
實務建議
成本、速度、品質的權衡:
- Minimal 配置:$10-20/month, ~600ms
- Standard 配置:$50-80/month, ~800ms
- Premium 配置:$150-300/month, ~1.5s
升級路徑:
Similarity Search
→ + Hybrid Search(優先)
→ + Reranking(提升品質)
→ + Query Transformation(複雜問題)
核心建議:
- 從簡單配置開始,驗證需求
- 優先加入 Hybrid Search(CP 值最高)
- 用 RAGAS 評估品質,找出瓶頸
- 根據瓶頸,加入對應的優化技術
- 記住:基礎做對比進階技術更重要
最後的建議:不要被複雜的技術嚇到。RAG 的核心概念很簡單:檢索相關文件,讓 LLM 基於文件回答。從最簡單的版本開始,根據實際需求逐步優化。記住:能用的系統比完美的架構更有價值。
希望這篇文章能幫助你理解並建立自己的 RAG 系統!
參考資料
- LangChain RAG Tutorial
- RAG Paper (Lewis et al., 2020)
- RAGAS Evaluation Framework
- LangGraph for Agentic Workflows
延伸閱讀
- RAG 典範轉移:從向量檢索到結構化檢索 — 補充視角:LangChain 自家 chatbot 重建案例,向量 RAG 到結構化檢索的演進
- 向量資料庫完全指南:為什麼 LLM 時代需要 Vector DB? — RAG 的底層工具:理解 Vector DB 的設計原理與選型
- LLM Agent 完整指南:從架構模式到實務應用 — 延伸:把 RAG 當成 Agent 的一個 tool,整合進多步驟 Agent 系統