你的 Prompt 為什麼有效:從 Transformer 機制看 AI 系統設計
有一次我在調一個 LLM 的 prompt,同樣的問題,把關鍵資訊放在 context 的前半段和後半段,得到的答案品質差很多。當下直覺是措辭的問題,調了半天,後來才意識到問題根本不在措辭——是在 Transformer 的注意力機制本身。
這件事讓我開始認真回去讀 Transformer 的原理,不是為了要訓練模型,而是想搞清楚這個每天在用的東西,到底是怎麼「讀」我給它的文字的。
讀完之後,很多原本覺得是玄學的 prompt 技巧突然變得可以解釋。context 為什麼要這樣排、memory 為什麼要設計成兩層、agent 跑幾十輪之後為什麼開始亂掉——這些都不是偶然,背後都有機制在跑。
讀完這篇,你會理解:
- 為什麼 context window 是有限的、需要被謹慎使用的資源,而不只是「API 算錢」的問題
- 為什麼重要資訊放在 context 的哪個位置,比你想的更重要
- 為什麼 agent 需要 Harness,而不是讓 LLM 自己記住東西
- 這些工程決策背後的「為什麼」,不只是 best practice 清單
這篇不是 Transformer 教學文,也不是 prompt 食譜。是從機制的角度,嘗試解釋為什麼好的 AI 系統設計長那個樣子。
一、從 RNN 到 Transformer:解法帶來的新代價
要理解 Transformer 為什麼長這樣,得先知道它在解什麼問題。
在 Transformer 之前,處理序列資料的主流是 RNN(Recurrent Neural Network)。RNN 的設計是這樣的:依序讀進每個 token,把「記憶」壓縮成一個 hidden state,傳遞給下一步。這個設計在短序列上還行,但有一個根本問題:梯度需要穿越每一個時間步才能更新早期的參數。序列一長,梯度不是消失就是爆炸——模型要嘛記不住遠端的資訊,要嘛訓練直接發散。LSTM 和 GRU 用 gate 機制緩解了這件事,但沒有根治,而且序列必須一步一步處理,無法平行化,訓練速度天花板很低。
Transformer 的解法是 self-attention:不再依序傳遞記憶,而是讓每個 token 直接和序列裡的所有其他 token 建立連結。「台灣的首都台北,是一個充滿活力的城市,這個城市⋯⋯」——「這個城市」要連結到「台北」,不需要梯度穿越中間所有的詞,直接連過去就好。長距離依賴問題消失了,平行計算也成為可能。
但這個解法有代價。
「讓每個 token 直接和所有其他 token 建立連結」,意思是要計算所有 token pair 的關係。序列長度為 n,就有 n × n 個 pair,計算量和記憶體用量都是 O(n²)。序列長度翻倍,計算量變四倍。這不是工程細節,這是架構上的基本約束——context window 有上限,是因為這個 O(n²) 的代價決定了你能負擔多大的序列。
這件事之後會一直出現,先記著。
二、三個你需要記住的機制
Self-Attention:所有 token 在競爭一個有限的注意力
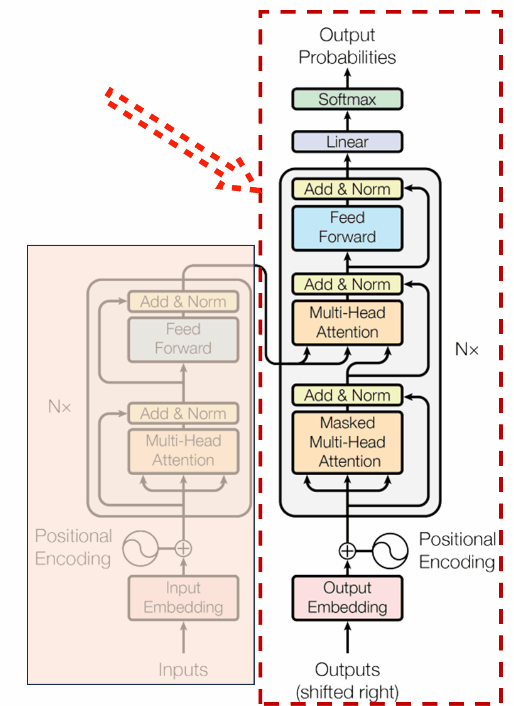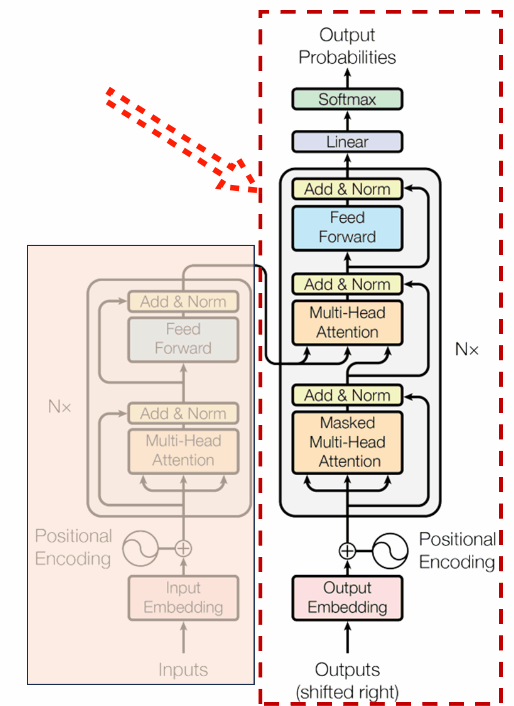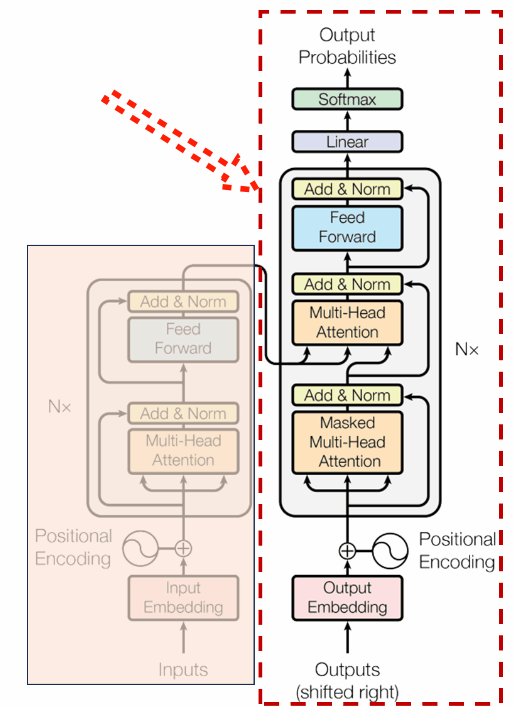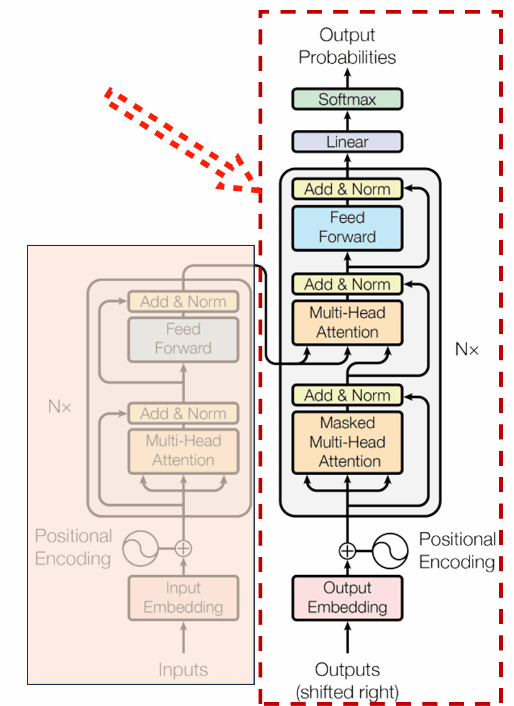
Self-attention 的計算邏輯是這樣的:每個 token 會生成三個向量——Query(我在找什麼)、Key(我能提供什麼)、Value(我的實際內容)。計算每個 token 的 Query 和所有 token 的 Key 的相似度,得到一組分數,再用 softmax 把它們轉成機率分布,最後用這個分布對所有 token 的 Value 做加權求和,得到這個 token 的輸出表示。
這裡有一個細節很重要:softmax 的輸出總和是 1。這表示注意力是零和競爭的。context 裡的 token 越多,每個 token 能分到的注意力就越被稀釋。相關的資訊不會消失,但它在競爭中的比重會下降。
這不是比喻,這是字面上的數學。
Positional Encoding:順序是後來加上去的
Self-attention 本身沒有位置概念。「貓吃魚」和「魚吃貓」對 attention 來說,如果詞的 embedding 一樣,計算結果一樣。為了讓模型知道 token 在序列中的位置,Transformer 會在 embedding 上加一個 positional encoding——可以是固定的 sinusoidal 函數,也可以是可學習的。
這個設計讓 Transformer 理解順序,但也意味著:位置是外加的信號,不是天生的。
Causal Masking:生成時只能往前看
現在主流的 LLM(GPT、Claude、LLaMA)都是 decoder-only 的架構。生成文字時,模型是自回歸的——一次生成一個 token,每個新 token 的 attention 只能計算它自己和前面所有 token 的關係,看不到「未來」的內容。這叫 causal masking。
你給 LLM 的 prompt 裡,排在前面的 token 影響後面所有的生成;排在後面的 token,對前面已生成的內容沒有影響。這條不對稱性,直接決定了指令放哪裡這個問題的答案。
三、Lost in the Middle:Attention 的物理弱點
有研究系統性地測試過這件事:把答案所需的關鍵資訊放在長 context 的不同位置,然後觀察模型的表現。結果很清楚——放在 context 的開頭和結尾,模型表現明顯好於放在中間。
這個現象被稱為「Lost in the Middle」。
機制上可以這樣理解:softmax 的競爭讓注意力更容易集中在局部顯著的位置(context 的邊界),而中間大量的 token 容易彼此稀釋。加上 causal masking 讓生成時的 attention pattern 本來就對近端 token 有偏好,中間段的資訊在競爭中天然處於劣勢。
這不是 bug,這是 Transformer 的幾何結構使然。它對工程設計的意義是:context 裡資訊的擺放位置不是審美問題,是工程問題。
四、從機制看 Prompt Engineering
知道這些之後,很多 prompt 技巧就不再是玄學了。
指令放前面。這不只是「讓模型先讀到」,而是 causal masking 的直接結果——放在最前面的指令,影響的是後面所有 token 的生成。如果你的 system prompt 在最前面說了「用繁體中文回答」,這個限制對後面整個生成過程都有效。放在後面說,效果打折。
Few-shot examples 的順序有意義。最後一個 example 離生成點最近,在 attention 裡的影響最強。如果你的 examples 品質不一,最好的一個放最後。
結構化的格式比散文描述有效。XML tag(<context>、<instruction>)、分段標題、分隔線——這些不只是視覺上整齊,它們在 token 層面幫助 LLM 建立 attention 的邊界,讓不同區塊的資訊不容易互相干擾。
「不要做 X」要謹慎。你寫了「不要提到 X」,token X 就進了 context。Self-attention 不管這個 token 在正面還是負面的語境裡出現,attention 還是會分配到它。更好的做法往往是正面描述你要什麼,而不是列出你不要什麼。
五、從機制看 Context Engineering
Context engineering 的核心問題是:這個有限的 O(n²) 預算,你要用來放什麼?
Context 不是 log dump。系統裡的每一條對話歷史、每一份文件,並不是放進去越多越好。放進去的每個 token 都在消耗注意力競爭的份額,也都在讓你真正想讓模型關注的東西變得更難被注意到。選擇放什麼進 context,是一個工程決策。
Retrieval 的本質。RAG(Retrieval-Augmented Generation)的存在理由,不只是「模型不知道最新的資料」。更根本的原因是:與其把整個知識庫都塞進 context(不現實,也會因為 Lost in the Middle 造成品質下降),不如在 call 之前先找出最相關的片段,讓它們出現在 context 的顯著位置。Retrieval 是在讓正確的 token 出現在 attention 能有效觸及的地方。
Memory 的設計取捨。如果要保留過去的對話記憶,raw history 和 summarized memory 各有代價。Raw history 保留細節,但佔用大量 token;summarized memory 壓縮了細節,但在 context 裡更精練。選哪種,取決於這個場景需要的是「精確回憶具體對話」還是「了解大方向的背景」。很多 agent 系統的記憶體設計都是兩層的原因也在這裡——per-session 的詳細記憶和跨 session 的知識萃取,用途不同,管理策略不同。
XML tag 的工程意義。在 context 裡用 <memory> 或 <knowledge_base> 這類 tag 包住不同來源的資訊,不只是讓 prompt 看起來整齊,而是在幫 LLM 形成清楚的 attention 邊界,讓它知道「這一段是背景知識,那一段是使用者的問題」,減少不同來源的資訊互相干擾的機率。
六、從機制看 Harness Engineering
說到這裡,有一件事要先講清楚:LLM 沒有跨 call 的 state。
每一次 LLM call,就是一次獨立的 forward pass。self-attention 只在這個 window 內計算,call 結束,中間的計算全部釋放。模型的 weight 沒有改變,也沒有任何機制讓它「記得上次說了什麼」。
你跟 ChatGPT 對話感覺它記得之前說的事,那個「記得」是工程做出來的,不是模型天生的。
Agent 如何製造記憶的假象? 常見的方法有三種:把整段對話歷史附加到下一次 call 的 context(最直接,但 context 會線性膨脹);維護外部 memory 存儲,每次 call 前選擇性載入相關內容;把重要的輸出存檔,下次 call 時注入。這三種方法不互斥,複雜的 agent 系統通常都混用。
Context 膨脹是必然的。如果用最直接的方法——每輪把所有歷史都加進去——context 每輪線性增長。結合 O(n²) 的 attention 代價,跑幾十輪之後,每次 call 的計算量和費用都會變得很可觀,最終超出 window 上限,模型開始截斷早期的資訊。
這就是 context compaction 存在的原因。你用 Claude Code 寫程式,對話跑到一定長度,工具會自動把之前的對話壓縮成摘要。這不是省錢的技巧,是解決 context 膨脹問題的工程手段。
Middleware 的注入時機。理解了 LLM 無 state 這件事,Harness 裡 middleware 的設計就很自然了:每次 LLM call 之前,middleware 負責把需要的 context 重新組裝好——當前的記憶、任務清單、可用的工具說明——然後注入到 system prompt 裡。這不是 workaround,這就是 agent 系統裡「讓 LLM 有連續感」的正確機制。
Progressive disclosure。不要一次把所有 context 都塞進 system prompt。如果 agent 有十個可用的 skill,不需要在每次 call 時把十個 skill 的完整說明都附上;附上名稱和一行描述就夠,讓 agent 在需要時自己去讀詳細內容。這個設計的邏輯和 context 管理一致:保留 token budget 給真正需要的東西。
Token budget 是資源,不是消耗品。把 context window 的 token 想成記憶體,而不是紙張。紙張你可以無限堆,記憶體滿了東西就開始掉。每一次 call 之前問自己:這個 token 放進去是在幫模型做更好的決策,還是在稀釋它對真正重要資訊的注意力?
結語
回到最開頭的那個問題:為什麼同樣的資訊放在不同位置,效果差這麼多?
現在你知道答案了:因為 softmax 的注意力競爭是零和的,因為 context 邊界位置在 attention 裡天然更顯著,因為 Lost in the Middle 不是玄學是幾何。
知道機制不會讓你的 prompt 立刻變好,但它給了你一個診斷語言。下次 LLM 給了奇怪的答案,你有能力問「是 context 裡的資訊放錯位置了?還是不相關的 token 稀釋了注意力?還是 agent 的記憶沒有正確地在這次 call 裡重建?」
這和照食譜調 prompt 是兩件不同的事。
結語:理解底層機制,讓你從「照教程寫 prompt」升級到「為問題設計解法」——而這個能力,在 AI 工具讓每個人都能快速產出的時代,才是真正的差異化。
延伸閱讀
- Harness Engineering — AI 工程師的第三個維度 — Transformer 機制的工程應對:Harness 就是在 stateless API 上建立 context 管理的基礎設施
- Frontier、Mini、還是自建:Production LLM 的架構沒有標準答案 — 模型機制之外的決策:Frontier vs Mini 的 context window 大小與成本取捨
- 在 Claude Code 的年代,我為什麼還要學 C++? — 往更底層走:從 Transformer 架構到推論引擎的 C++ 核心