把 ML 工程師的直覺,打包進 Agent
一個 ML 轉 Backend 工程師的想法
我的背景是 ML,後來刻意往 Backend 走,想學怎麼把想法打造成一個完整的系統。
在 ML 的時候,每次看到新的 Kaggle 比賽,有個習慣動作:去翻 top solution 的 notebook,看高手在用什麼方法,為什麼這樣做,評估指標背後的邏輯是什麼。這個過程花時間,但是值得——它讓你的 ML 直覺越來越準。
問題是,那些知識很難沉澱。讀完一個 notebook,insight 留在腦子裡,很快就淡掉。換下一場比賽,又從零開始。
這個問題一直放在腦子裡。往 Backend 走之後,兩個背景加在一起,我覺得有能力把這件事做成一個真正能跑的系統:這個 research process 本質上是可以系統化的,你需要的不是更勤勞地讀 notebook,而是一個會累積知識的系統。
更大的圖景是這樣的:第一步,讓 agent 幫你讀、幫你整理別人的知識。第二步,讓 agent 幫你跑實驗,把每一次實驗的結果也變成知識。再往後,接上 AutoResearch——定義好評估指標和搜索邊界,agent 就能自主跑實驗迴圈,你睡一覺,醒來有一份實驗報告。
ML 工程師的角色,從「親自跑實驗的人」,變成「設計讓 agent 學什麼的人」。
llm-kaggle-agent 是這條路的第一步。
核心想法:ML 工程師的「判斷力」可以被編碼
這個 project 的核心不是「讓 AI 讀 notebook」。那只是爬蟲。
核心是:每一次分析,都讓系統更懂 ML。
Agent 分析完一場 Kaggle 比賽之後,不只生成報告,還會蒸餾出 generalizable insights——這類問題用什麼方法有效、evaluation metric 的選擇邏輯、資料特性怎麼影響建模決策。這些 insights 存進知識庫,下次分析另一場比賽時,這些知識就在 context 裡。
累積夠了之後,你可以切換到 chat mode,直接問:「我有一個時序預測問題,目標是 MAPE,資料有大量缺失值,我該從哪個方向開始?」Agent 會用它研究過的所有競賽知識來回答,而不是憑空生成。
這才是真正有意義的地方:把 ML 工程師花在 research 上的時間,轉換成一個可以持續對話的 ML 專家。
這個 POC 在做什麼
兩個 mode,針對不同場景:
# 搜尋競賽,選定後自動分析 top solution
uv run kaggle-agent analyze "house prices"
# 用累積的知識庫進行專家對話
uv run kaggle-agent chat
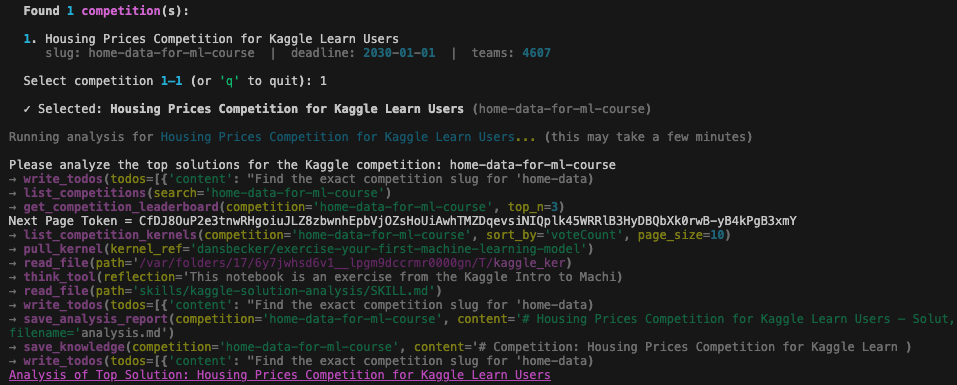
analyze mode 的流程:搜尋 Kaggle 競賽 → 用戶確認選哪場 → agent 找出最高票的 solution notebook → 下載並分析 → 生成結構化報告 → 蒸餾 generalizable knowledge 存進知識庫。
chat mode 的流程:載入所有累積的知識庫 → 開啟互動對話。不重新分析,直接用已有知識回答問題。
兩個 mode 的切換點在記憶體載入策略,這也是整個系統設計最值得深談的部分。
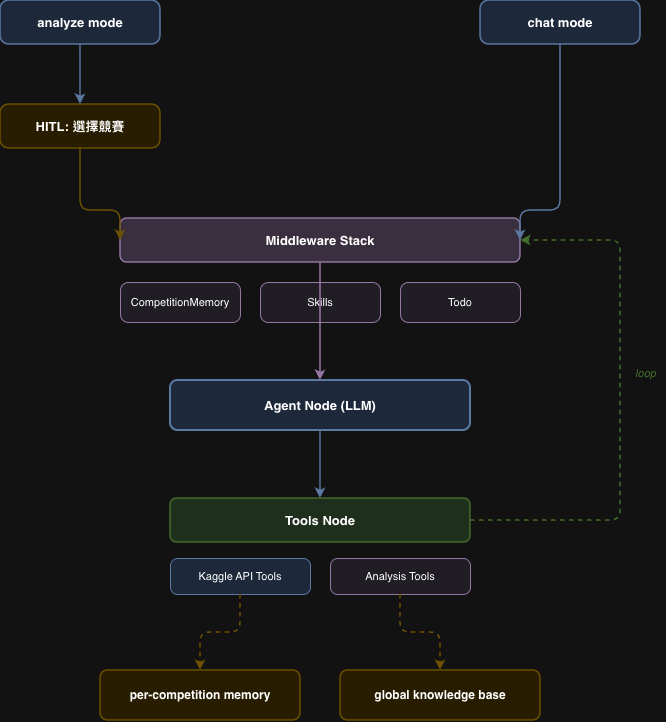
架構概覽
整個系統分三層:
CLI 層:使用者介面,包含競賽選擇的 HITL 流程和 token usage 顯示。
Agent 層:LangGraph 圖。一個 agent node 和一個 tool node 組成的循環,由 Middleware Stack 在每輪 LLM call 前注入 context。
工具層:兩組 tools——Kaggle API tools(操作 Kaggle 平台)和 Analysis tools(思考、存檔、知識提煉)。
記憶體系統橫跨三層:per-competition memory 和 global knowledge base 分別在不同 mode 下載入,透過 middleware 注入 system prompt。
最核心的設計:兩層記憶體
這是整個 project 設計上最重要的決策。
memory/
├── titanic.md # per-competition memory
├── house-prices-advanced.md
└── knowledge/
├── titanic.md # distilled ML insights
└── house-prices-advanced.md
第一層:per-competition memory(memory/{slug}.md)
每場比賽有自己的記憶檔案,記錄這場比賽的分析歷史和 agent 累積的觀察。analyze mode 只載入當前比賽的這個檔案——分析 Titanic 不需要知道 House Prices 的細節。
第二層:global knowledge base(memory/knowledge/*.md)
save_knowledge tool 在分析完成後被呼叫,從比賽中提煉出 generalizable insight——不是「Titanic 比賽的冠軍用了 XGBoost」,而是「在 binary classification 問題中,當正負樣本不均衡且 AUC 是指標時,這些特徵工程手法有效」。
chat mode 會把 knowledge/ 下所有檔案全部載入,合併成一個大的 context。這才是 chat mode 的底氣——它回答的每個問題背後,是所有分析過的比賽。
為什麼分兩層?
一個直覺的設計是把所有東西都放在同一個地方,每次都全部載入。問題是,analyze mode 時載入大量無關的知識會干擾 context,也浪費 token。分層讓兩個 mode 各自只載入自己需要的東西。
save_knowledge 的設計是這個分層的關鍵。Agent 被明確引導:存進知識庫的東西必須是 generalizable 的,不能是 competition-specific trivia。這個 prompt 設計讓知識庫隨著時間越來越有價值,而不是越來越雜。
Tools 設計哲學
Tools 設計哲學
Kaggle API Tools
四個工具讓 agent 能真正操作 Kaggle:
list_competitions:搜尋符合關鍵字的競賽get_competition_leaderboard:查看排名前幾的隊伍list_competition_kernels:列出競賽下的 notebooks,預設按票數排序pull_kernel:下載 notebook 原始碼到本地
這組工具的設計考量是讓 agent 自己決定分析策略。系統不硬寫「分析第一名的 notebook」,而是讓 agent 看 kernel list,判斷哪個值得深讀(高票且是 solution,不是 EDA tutorial),然後自己決定要 pull 哪幾個。
think_tool:讓思考變成一個 tool call
@tool
def think_tool(reflection: str) -> str:
"""Strategic reflection on analysis progress and decision-making."""
return f"Reflection recorded: {reflection}"
這個 tool 不做任何事——它只是收到一個 string,回傳確認訊息。
它存在的理由:強制 agent 在關鍵決策點做顯式推理。
沒有 think_tool 時,agent 可能在讀完一個 notebook 之後直接跳到下一步,不停下來整理。有了 think_tool,system prompt 可以明確指示「分析完每個 kernel 後,先呼叫 think_tool 整理發現,再決定下一步」。這讓分析過程更可控,也讓 chain-of-thought 出現在 tool call log 裡,方便 debug。
save_knowledge vs save_analysis_report
兩個工具對應兩種輸出,用途截然不同:
save_analysis_report 存的是這場比賽的完整分析——task framing、資料特性、模型細節、比賽排名邏輯。是比賽維度的紀錄。
save_knowledge 存的是從這場比賽抽象出來的 ML 知識。Agent 被明確告知:專注在 generalizable 的部分,略去比賽特有的細節。是知識維度的提煉。
設計上,save_knowledge 應該在 save_analysis_report 之後呼叫,先有完整分析,再做蒸餾。
Middleware Stack:三層 Context 注入
每次 LLM call 前,三個 middleware 依序把 context 疊進 system prompt:
CompetitionMemoryMiddleware:注入 per-competition memory,以及(chat mode 時)全部知識庫。用 XML 標籤區分:<competition_memory> 和 <ml_knowledge_base>,讓 LLM 清楚辨別資訊來源。
SkillsMiddleware:掃描 skills/ 目錄,只注入 skill 的名稱和一句 description(不是全文)。Agent 需要時才用 read_file 讀完整內容。這是 progressive disclosure——不把所有 workflow 指令都塞進 system prompt,按需供給。
TodoMiddleware:把當前的 todo list 渲染成 checkbox 格式注入 system prompt,讓 LLM 隨時知道哪些任務待完成、哪個正在進行。
Middleware 的實作遵循同一個 pattern:before_agent(初始化,只跑一次)+ inject_system(每輪注入),讓每個 middleware 的職責清楚分離。
HITL:在哪裡放護欄
這個 project 的 HITL 放在 CLI 層,不是 LangGraph 的 interrupt 機制:
$ uv run kaggle-agent analyze "house prices"
Found 8 competition(s):
1. House Prices - Advanced Regression Techniques
slug: house-prices-advanced-regression-techniques | deadline: — | teams: 76,953
2. ...
Select competition 1–8 (or 'q' to quit): 1
✓ Selected: House Prices (house-prices-advanced-regression-techniques)
用戶在 agent 啟動之前就確認了要分析哪場比賽。確認後,agent 全自動跑完,不再中斷。
這個設計的邏輯:HITL 放在代價最高的決策點。選錯競賽會導致整個分析跑偏,那才是最需要人類確認的地方。分析過程中的每個 tool call(下載哪個 kernel、分析幾個 notebook)讓 agent 自己判斷反而更有效率,因為那些決策需要 ML 領域知識,人類介入意義不大。
相比之下,deepagents 的 HITL 放在 graph 層的 interrupt,攔截每個寫入操作。那個設計適合通用場景——你不知道 agent 會寫什麼。這個 project 的 agent 只寫 report 和 knowledge,操作目標清楚,CLI level HITL 就夠了。
選擇 HITL 的位置,本質上是在問:哪個決策最需要人類判斷?
展望:從 Research 到實驗迴圈
目前的 Phase 1 解決的是 research 問題:把「讀別人的解法」轉換成知識,來源是外部的(Kaggle top solutions)。
Phase 2 的方向是往 prototyping 走:知識庫夠豐富之後,agent 不只告訴你什麼方法有效,而是直接 scaffold starter code,壓縮從「拿到新問題」到「有一個可以跑的 baseline」的時間。
但更有意思的是 Phase 2 之後的可能性。
知識來源從外部變內部:Prototype 跑起來之後,每一次實驗的結果——哪個方向有效、哪個假設被推翻——本身就是新的 ML 知識。如果 agent 能讀 experiment logs(MLflow、W&B 記錄的 metrics 和 artifacts),就能把「我們在這類資料上試過 X 方法,得到了 Y 改善」這件事更新進知識庫。知識不再只來自讀 notebook,而是來自自己跑過的每一次實驗。
從學習轉向自主探索:當知識庫累積到一定量,可以接上 AutoResearch 的模式——工程師定義好評估指標和搜索邊界,agent 就進入完全自主的實驗迴圈:提出想法、修改 code、跑實驗、讀結果、決定 keep 或 discard、繼續下一輪。整個過程不問人,直到人手動停止。
這和 AutoML 的差異在於,agent 不只調超參數,它可以改架構、改 optimizer、改訓練策略——任何它認為值得試的方向都可以嘗試。你睡一覺,醒來有 100 個實驗結果等你看。
Engineer 的角色在哪裡:AutoResearch 的 HITL 不在迴圈中,而是在迴圈的兩端。
- 開始前:定義什麼是固定的(evaluation harness、metric 定義),什麼是自由的(架構、超參數)。這個邊界劃得好不好,決定 agent 探索的品質。如果 metric 定義錯了,agent 會很努力地優化一個錯的目標。
- 結束後:審閱 agent 的實驗紀錄,決定哪些發現值得帶進下一個 phase。不是所有 val_bpb 改善都值得保留——有些改善代價太高(複雜度、VRAM),工程師需要做這個 trade-off 判斷。
這是 ML 工程師這個角色最有趣的轉變方向:從「親自跑實驗的人」變成「設計搜索空間和評估標準的人」。
完整的 project 在 llm-kaggle-agent。
結語:ML 工程師的價值不只是會跑模型,而是知道在什麼問題用什麼方法,以及為什麼。這個判斷力過去只能靠自己慢慢累積。現在,它可以被編碼進一個會持續學習的系統。
延伸閱讀
- AI 自主研究實驗:讓 Agent 在你睡覺時跑 100 個實驗 — 同樣的 autoresearch 概念用在 Titanic:100 個實驗的完整實戰記錄
- 不靠直覺,靠實驗:用 AutoResearch 找到 C++ 的 33x 優化空間 — autoresearch 的另一個應用場景:C++ 推論效能優化的實驗設計
- AI Agent 大語言模型輸出評估:如何選擇最佳評估框架? — ML Agent 的評估設計:如何系統化衡量 Agent 的實驗決策品質