LLM Agent 四大架構模式:選型指南
第一次需要在系統中加入 Agent 能力時,我花了太多時間在框架選型上——LangChain 還是 LangGraph?ReAct 還是 Plan-and-Execute?
後來發現,選錯框架只是小問題,選錯架構模式才是真正的坑:用 ReAct 處理一個簡單的工具調用任務,成本是 Tool Calling 的 20 倍;用 Plan-and-Execute 處理一個需要動態調整的任務,計畫在第二步就失效了。
架構模式的選擇,比任何框架細節都重要。
讀完精華版(2 分鐘),你會理解:
- 四大模式的本質差異與 LLM 調用成本
- 選型的三個關鍵問題
- 從簡單到複雜的升級路徑
精華版
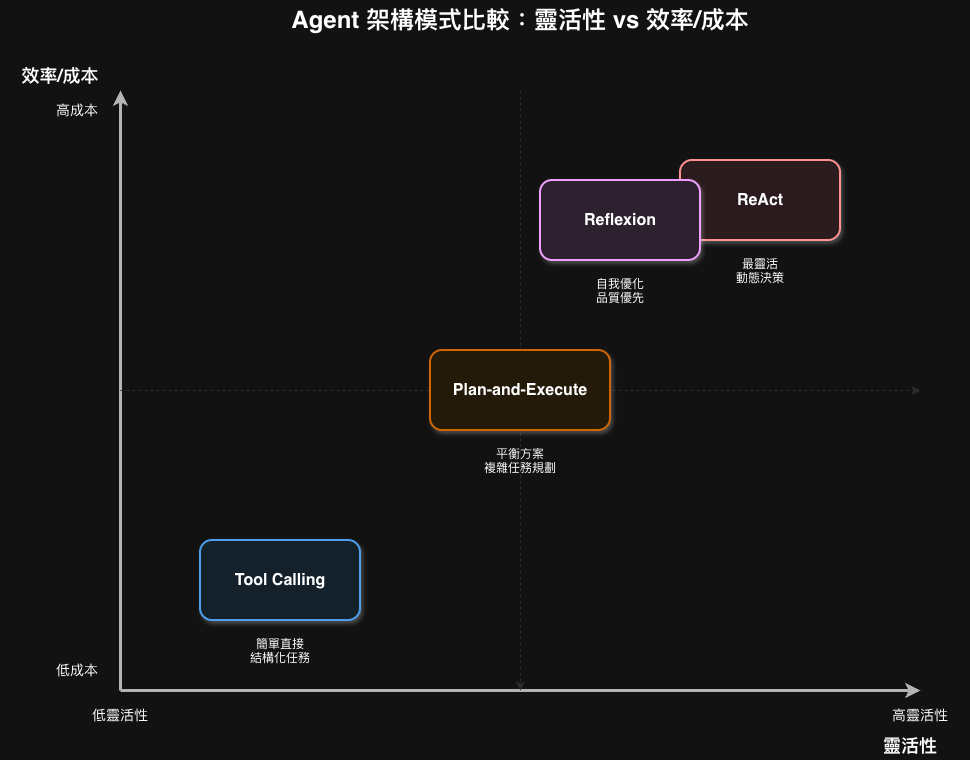
四大模式對比
| 模式 | 核心機制 | LLM 調用次數 | 最佳場景 |
|---|---|---|---|
| Tool Calling | 單次決策 → 執行 | 1–2 次 | 工具明確、任務不需多輪推理 |
| Plan-and-Execute | 先規劃再執行 | 1 + N 次 | 步驟可預測的確定性任務 |
| ReAct | 推理 ↔ 行動交替 | N 次(每步一次) | 執行路徑無法預知的動態任務 |
| Reflexion | 生成 → 反思 → 改進 | N × 3 次 | 品質優先、latency 不敏感 |
每個模式的核心是什麼
- Tool Calling:LLM 單次決定「呼叫哪些工具、傳什麼參數」,系統執行後直接回傳;工具數量少且任務不需要多輪推理時的預設選擇。
- Plan-and-Execute:LLM 先一次性生成完整執行計畫,再依序執行;任務步驟可預測時比 ReAct 省下約 50% token 成本。
- ReAct:每次行動前 LLM 重新推理、行動後觀察結果再決定下一步;適合執行路徑無法預先規劃的探索性任務。
- Reflexion:生成答案後再用一次 LLM 自我評估,根據評估迭代改進;品質要求高且不在意延遲時才值得。
選型的三個關鍵問題
1. 這個任務需要幾步才能完成?
1–2 步用 Tool Calling,直接最省。需要 3 步以上,才考慮其他模式。這個問題能淘汰掉大多數「其實不需要 Agent」的場景。
2. 執行前能預知所有步驟嗎?
能預知 → Plan-and-Execute,一次規劃省掉多輪 LLM 調用。不能預知(中間結果會影響下一步)→ ReAct,保持每步決策的靈活性。
3. 成本是瓶頸嗎?
Reflexion 的成本是 Tool Calling 的 15–30 倍。品質要求不到極高,這個差距很難值回票價。
以下是完整版,按需取用。
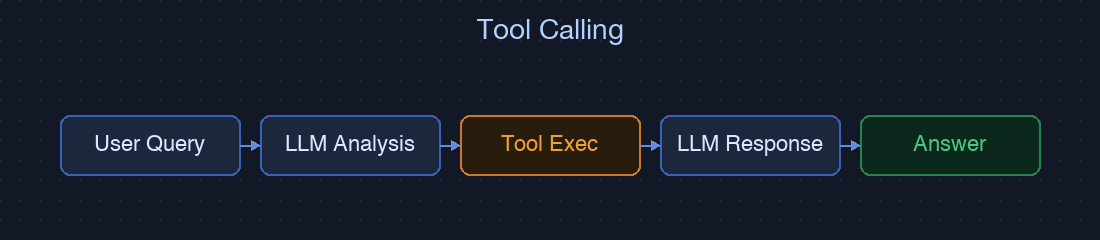
Tool Calling
核心機制
Tool Calling 是最接近「傳統函式調用」的 Agent 模式。LLM 接收到請求後,一次性分析出需要呼叫哪些工具、傳入什麼參數,接著系統執行這些工具,把結果回傳給 LLM 生成最終答案。
整個過程通常只需要 1–2 次 LLM 調用,沒有中間迭代。這個模式的上限很清楚:它不會「思考要不要改變策略」,只做一次決策。
優勢
- 效率高:通常只需 1–2 次 LLM 調用
- 結果可預測:單次決策,行為穩定
- 容易除錯:工具調用格式標準化
- 原生支援:OpenAI、Anthropic、Google 都有內建 API
劣勢
- 無法多輪推理:單次決策,遇到複雜任務就力不從心
- 依賴工具定義品質:工具描述不清楚,LLM 會選錯工具
- 沒有觀察機制:工具執行後無法根據結果調整策略
適用場景
- 工具數量有限(1–5 個)且明確定義
- 需要快速響應的場景(聊天機器人、即時查詢)
- 任務邏輯清晰、不需要根據中間結果改變方向
工程洞察:工具數量超過 5 個後,LLM 選錯工具的概率會顯著上升,這是考慮切換到 ReAct 的訊號。
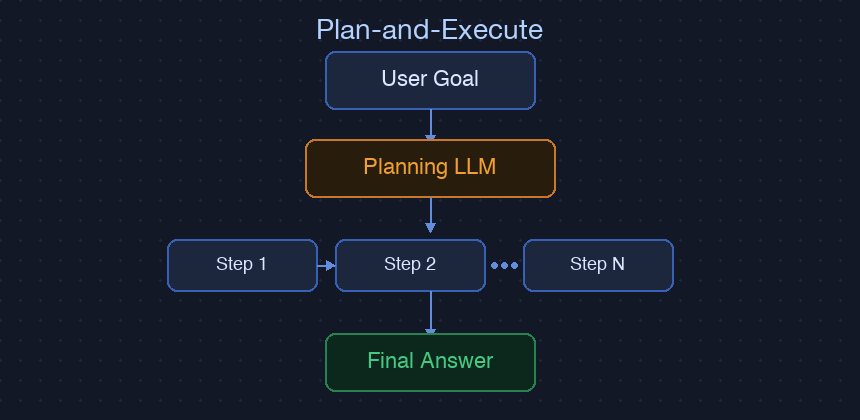
Plan-and-Execute
核心機制
Plan-and-Execute 把 Agent 的工作分成兩個明確的階段。第一階段:LLM 一次性生成完整的執行計畫,把目標拆解成有序步驟。第二階段:系統按照計畫依序執行,不再重新調用 LLM 做決策。
這個設計的核心假設是「任務路徑可以預先規劃」。一旦這個假設成立,它就比 ReAct 高效得多——規劃只用一次 LLM,後續執行不再有推理成本。
優勢
- Token 效率高:規劃只需一次 LLM 調用,相比 ReAct 節省 40–60%
- 步驟透明:計畫生成後一目了然,容易預先審查
- 適合確定性任務:步驟間依賴明確、執行順序固定
劣勢
- 缺乏靈活性:計畫生成後無法根據中間結果調整
- 計畫失效即全盤失敗:步驟 2 出錯不會自動改道
- 對規劃 prompt 要求高:弱模型容易生成缺漏的計畫
適用場景
- 目標明確、步驟可在執行前完整列出
- 需要在成本和靈活性之間取得平衡
- 「下載資料 → 分析 → 產生報告」這類線性流程
工程洞察:計畫品質取決於規劃階段的 prompt 設計,弱模型生成的計畫往往缺少錯誤處理分支,上 Production 前要測試失敗路徑。
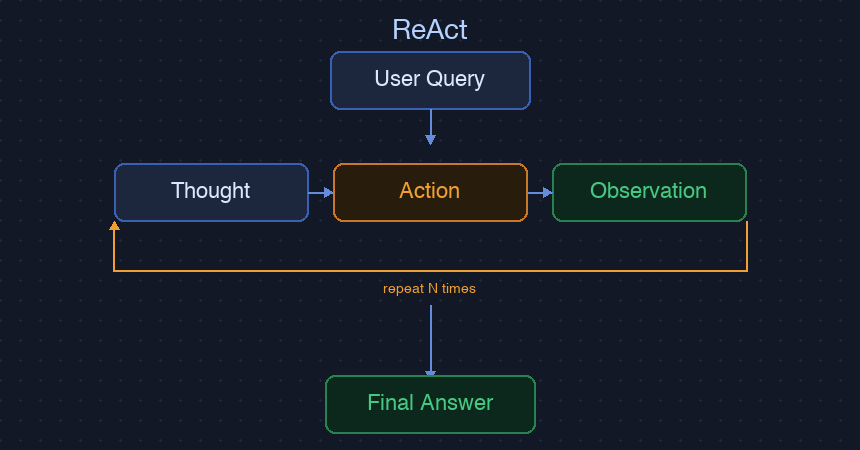
ReAct
核心機制
ReAct 是 Reasoning + Acting 的縮寫。Agent 在每次行動前都先推理(Thought),執行後觀察結果(Observation),再決定下一步。這個「思考 → 行動 → 觀察」的循環會一直重複,直到任務完成。
與 Plan-and-Execute 的「先想好再做」不同,ReAct 是「邊做邊想」。每一步的決策都基於當下的最新觀察,這讓它能應對計畫階段無法預見的情況。代價是每個步驟都需要一次 LLM 調用,10 步驟的任務就是 10 次 API call。
優勢
- 靈活性高:能根據中間結果動態調整策略
- 可解釋性強:每個 Thought 都記錄了 LLM 的推理過程
- 適合探索性任務:不需要預先知道所有步驟
劣勢
- Token 消耗大:每次迭代包含完整的 Thought + Action + Observation
- 容易陷入循環:LLM 可能重複執行相同動作而沒有進展
- 成本難以預估:步驟數量不確定,成本上限模糊
適用場景
- 執行路徑依賴中間結果(例:根據搜尋結果決定下一個搜尋方向)
- 需要動態決策的客服、研究類任務
- 工具調用順序在任務開始前無法確定
工程洞察:ReAct 的 token 消耗隨步驟數線性成長,超過 15 步時需要評估是否改用有上限的 Plan-and-Execute,或加入強制終止條件。DeerFlow、HolmesGPT、HermesAgent 的核心 loop 都是 ReAct——這幾乎是所有真實 Agent 系統的預設選擇。
Reflexion
核心機制
Reflexion 在 ReAct 的基礎上加入了自我評估迴圈。Agent 生成答案後,不直接回傳,而是再用一次 LLM 評估輸出品質——這個答案是否完整?有沒有錯誤?如何改進?根據評估結果,Agent 修改答案再評估,直到品質達標或到達迭代上限。
這個模式類似人類的「寫初稿 → 自我檢視 → 修改 → 再檢視」過程。它不改變任務的執行方式,而是在輸出端加上品質把關機制。
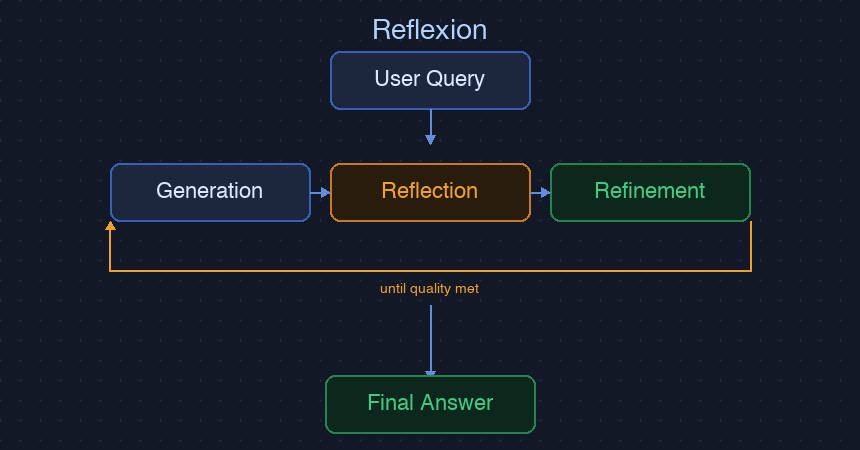
優勢
- 輸出品質高:透過迭代改進逐步提升
- 評估標準可控:明確定義品質門檻
- 適合高要求任務:技術文件撰寫、程式碼生成
劣勢
- 成本高:每輪迭代需要 Generation + Reflection + Refinement 三次 LLM 調用
- 速度慢:多輪迭代累積的延遲顯著
- 可能過度優化:評估標準定義不清時,反覆修改反而降低品質
適用場景
- 有明確品質標準的輸出(程式碼正確性、報告完整性)
- Cost 與 Latency 不是主要瓶頸
- 無法用人工 review 每一次輸出的大量自動化任務
工程洞察:自我評估的標準需要明確定義,否則 LLM 傾向給自己打高分並提早停止迭代——「答案還不錯」是最常見的失效模式。HermesAgent 的 Skill Nudge(每 10 次工具調用後自動評估是否需要建立新技能)和 GenericAgent 的 Goal Mode(以時間預算驅動持續迭代直到收口)都是這個模式的輕量實作。
決策輔助
架構選擇矩陣
| 需求特徵 | 推薦架構 | 原因 |
|---|---|---|
| 簡單工具調用(1–3 個工具) | Tool Calling | 最低成本,足夠用 |
| 動態任務(步驟依賴中間結果) | ReAct | 每步重新決策 |
| 固定流程(步驟可預測) | Plan-and-Execute | 省 40–60% token |
| 高品質輸出(有明確評估標準) | Reflexion | 迭代改進品質 |
成本對比(以 GPT-4 為例)
| 架構 | LLM 調用次數 | 平均 Token | 每次任務成本 |
|---|---|---|---|
| Tool Calling | 1–2 次 | 500–1,000 | ~$0.015–0.03 |
| Plan-and-Execute | 1 + N 次 | 2,000 | ~$0.06 |
| ReAct(10 步) | 10 次 | 10,000 | ~$0.30 |
| Reflexion(3 輪) | 6–9 次 | 15,000+ | ~$0.45+ |
升級路徑
從最簡單的模式開始,讓實際瓶頸驅動升級:
Tool Calling(先驗證需求)
↓ 任務需要多步驟且路徑不固定?
ReAct(保持靈活性)
↓ 步驟開始可預測、成本上升?
Plan-and-Execute(優化效率)
↓ 輸出品質成為主要問題?
Reflexion(迭代改進)能用簡單模式解決的,就不要用複雜模式。架構選型的核心是「夠用就好」,而不是「功能最強」。
參考資料
- ReAct: Synergizing Reasoning and Acting in Language Models
- Reflexion: Language Agents with Verbal Reinforcement Learning
- LangGraph Documentation
延伸閱讀
- RAG System 完整指南:從原理到實踐 — Agent 最重要的工具之一:把 RAG 作為 tool 整合進 Agent 的完整設計
- 打開原始碼才發現:三個 Agent 框架,三種截然不同的設計哲學 — 從原始碼層次看 Agent 設計:deepagents、openclaw、hermes 三種哲學
- 從一個任務出發:怎麼疊加一個夠用的 Agent 系統 — 實戰指南:從 Agent 架構理論到可以跑的系統,怎麼一步一步疊加