LLMOps
Langfuse
2025-11-03 · — views

在大語言模型(LLM)應用快速發展的時代,如何有效地監控、評估和改進 AI 系統成為了開發者面臨的重要挑戰。Langfuse 作為一個專為 LLM 應用設計的可觀測性和實驗平台,為開發團隊提供了全面的解決方案。
什麼是 Langfuse?
Langfuse 是一個開源的 LLM 工程平台,專注於幫助開發者構建可靠、可測量的 AI 應用。它結合了以下核心功能:
🔍 可觀測性(Observability)
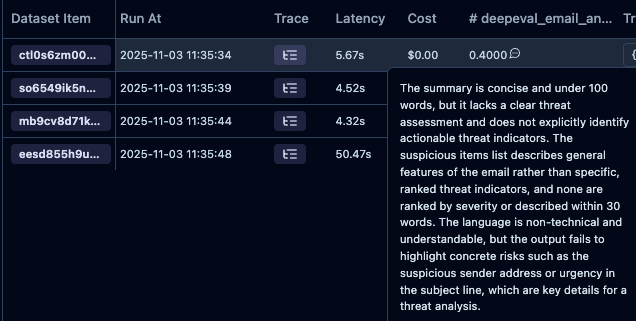
- Trace 追蹤:完整記錄 LLM 應用的執行流程,包括輸入、輸出、延遲和成本
- 實時監控:監控應用性能指標、API 使用情況和錯誤率
- Debug 支援:快速定位和診斷生產環境中的問題
📊 評估與實驗(Evaluation & Experimentation)
- Dataset 管理:建立和管理測試資料集,支援版本控制
- 實驗框架:系統化地比較不同模型、提示詞和參數配置
- 評估指標:整合多種評估方法,量化模型表現
💰 成本分析(Cost Analytics)
- 使用量追蹤:精確統計 token 消耗和 API 呼叫次數
- 成本控制:設定預算警告,避免意外的高額費用
- 效能優化:識別成本高但效果有限的操作
🤝 團隊協作(Team Collaboration)
- 共享儀表板:團隊成員可以共同查看和分析數據
- 角色管理:靈活的權限控制系統
- 註釋功能:為重要的 trace 添加標記和註解
Langfuse 的核心價值
1. 生產環境準備度
傳統的 LLM 開發往往缺乏生產環境的可見性。Langfuse 提供:
- 完整的請求生命週期追蹤
- 性能瓶頸識別
- 異常行為檢測
2. 數據驅動的改進
通過系統化的數據收集和分析:
- 量化不同版本的改進效果
- 識別用戶行為模式
- 基於真實數據做決策
3. 開發效率提升
- 快速實驗迭代
- 自動化評估流程
- 簡化部署和監控
實戰演示:使用 Langfuse 和 DeepEval 構建評估系統
接下來,我們將展示如何結合 Langfuse 和 DeepEval 構建一個完整的 LLM 評估系統。這個示例展示了如何對文本分析任務進行系統化評估。
核心組件說明
1. Azure OpenAI 整合
首先,我們需要建立 DeepEval 與 Azure OpenAI 的橋接:
class AzureOpenAI(DeepEvalBaseLLM):
"""Custom Azure OpenAI LLM for DeepEval integration."""
def __init__(self, model):
self.model = model
def load_model(self):
return self.model
def generate(self, prompt: str) -> str:
chat_model = self.load_model()
return chat_model.invoke(prompt).content
async def a_generate(self, prompt: str) -> str:
chat_model = self.load_model()
res = await chat_model.ainvoke(prompt)
return res.content
def get_model_name(self):
return "Custom Azure OpenAI Model"
這個類別允許我們在 DeepEval 框架中使用 Azure OpenAI 服務。
2. 實驗系統初始化
class LangfuseDeepEvalExperiment:
"""整合 Langfuse Dataset 和 DeepEval 的實驗系統."""
def __init__(self):
# 設置 Langfuse 連接
self.public_key = os.getenv("LANGFUSE_PUBLIC_KEY")
self.secret_key = os.getenv("LANGFUSE_SECRET_KEY")
self.host = os.getenv("LANGFUSE_HOST")
# 初始化客戶端
self.langfuse = get_client()
# 設置 Azure OpenAI
self.azure_openai = AzureChatOpenAI(
azure_deployment="your-deployment-name",
azure_endpoint="https://your-resource.openai.azure.com/",
api_version="2024-02-15-preview",
api_key="your-api-key",
temperature=0.0,
max_tokens=1000
)
3. 自定義評估指標
使用 DeepEval 的 GEval 建立評估指標:
def create_deepeval_metrics(self) -> List:
"""創建 DeepEval 評估指標."""
from deepeval.test_case import LLMTestCaseParams
text_analysis_metric = GEval(
name="Text Analysis Quality",
criteria="""
Evaluate the quality of text analysis based on:
1) Analysis provides clear, concise explanation within 100 words
2) Key insights are well-structured and relevant
3) Language is professional and easy to understand
4) Conclusions are well-supported by the content
""",
evaluation_params=[
LLMTestCaseParams.INPUT,
LLMTestCaseParams.ACTUAL_OUTPUT
],
threshold=0.7,
model=self.deepeval_model,
verbose_mode=True
)
return [text_analysis_metric]
4. 任務執行函數
定義實際的分析任務:
def text_analysis_task(self, *, item, **kwargs):
"""Text analysis task function for Langfuse experiment."""
try:
# 從 Langfuse dataset item 獲取輸入
item_input = item.input
# 創建分析輸入物件
analysis_input = {
'case_id': item_input.get('case_id', f'task_item'),
'content': item_input.get('content', ''),
'metadata': item_input.get('metadata', {}),
'analysis_type': item_input.get('analysis_type', 'general')
}
# 執行文本分析
analysis_result = perform_text_analysis(analysis_input)
return analysis_result
except Exception as e:
return {
"error": str(e),
"summary": "Analysis failed",
"key_insights": []
}
5. 評估器函數
將分析結果轉換為 DeepEval 可處理的格式:
def deepeval_evaluator(self, *, input, output, metadata, **kwargs):
"""DeepEval evaluator function for Langfuse experiment."""
from langfuse import Evaluation
try:
# 處理輸入格式
item_input = input.input if hasattr(input, 'input') else input
# 構建評估用的測試案例
analysis_type = item_input.get('analysis_type', 'general')
content_length = len(item_input.get('content', ''))
input_query = f"Analyze the following content (Type: {analysis_type}, Length: {content_length} chars)"
actual_output = json.dumps(output, ensure_ascii=False, indent=2)
# 創建 DeepEval TestCase
test_case = LLMTestCase(
input=input_query,
actual_output=actual_output,
retrieval_context=[f"Text analysis for {analysis_type} content"]
)
# 執行評估
metrics = self.create_deepeval_metrics()
evaluation_results = evaluate([test_case], metrics)
# 提取分數
score = self.extract_score_from_results(evaluation_results)
return Evaluation(
name="deepeval_text_analysis_quality",
value=score,
comment=f"DeepEval assessment completed with score: {score}"
)
except Exception as e:
return Evaluation(
name="deepeval_text_analysis_quality",
value=0.0,
comment=f"Evaluation failed: {str(e)}"
)
6. 運行完整實驗
最後,整合所有組件運行實驗:
def run_deepeval_experiment(self, dataset_name: str, experiment_name: str):
"""運行 DeepEval 實驗 - 使用 Langfuse SDK."""
try:
# 獲取 dataset
dataset = self.get_dataset(dataset_name)
# 使用 Langfuse SDK 運行實驗
result = dataset.run_experiment(
name=experiment_name,
description=f"DeepEval text analysis evaluation - {datetime.now()}",
task=self.text_analysis_task,
evaluators=[self.deepeval_evaluator],
max_concurrency=1, # 控制並發避免 API 限制
metadata={
"evaluation_framework": "deepeval",
"model": "gpt-4.1",
"evaluation_type": "text_analysis",
"experiment_timestamp": datetime.now().isoformat()
}
)
print(f"✅ Experiment completed!")
print(f"🌐 View results at: {self.host}")
return result
except Exception as e:
print(f"❌ Error running experiment: {e}")
raise
實驗結果分析
運行實驗後,您將在 Langfuse 儀表板中看到:
📊 性能指標
- 每個測試案例的評估分數
- 平均處理時間
- 成功率統計
🔍 詳細追蹤
- 完整的輸入輸出記錄
- 評估過程的詳細日誌
- 錯誤和異常的堆疊追蹤
💡 改進建議
- 識別表現較差的測試案例
- 分析失敗模式
- 優化提示詞和參數
最佳實踐建議
1. 數據集設計
- 包含多樣化的測試案例
- 確保數據品質和標註準確性
- 定期更新和擴充測試集
2. 評估指標選擇
- 結合自動化和人工評估
- 設計領域特定的評估標準
- 使用多個互補的指標
3. 實驗管理
- 清晰的命名規範
- 詳細的實驗文檔
- 版本控制和回滾機制
4. 監控和警告
- 設置關鍵指標的閾值警告
- 定期檢查成本和性能趨勢
- 建立異常檢測機制
結論
Langfuse 為 LLM 應用開發提供了強大的工具集,從開發階段的實驗到生產環境的監控,涵蓋了完整的生命週期。通過與 DeepEval 等評估框架的整合,開發者可以建立起系統化、數據驅動的 AI 應用改進流程。
在快速變化的 AI 領域,可觀測性不僅僅是 nice-to-have,而是 must-have。Langfuse 幫助團隊在這個充滿挑戰和機遇的時代,構建更可靠、更透明的 AI 系統。
延伸閱讀
- AI Agent 大語言模型輸出評估:如何選擇最佳評估框架? — Langfuse 的互補工具:DeepEval、Promptfoo 等評估框架的選型指南
- Frontier、Mini、還是自建:Production LLM 的架構沒有標準答案 — 監控之前的決策:選對模型才能讓 Langfuse 的數據有意義
- Harness Engineering — AI 工程師的第三個維度 — 可觀測性是 Harness 的一個維度:理解 Langfuse 在整體 AI 基礎設施的位置