Harness Engineering — AI 工程師的第三個維度
三個詞,三種不同的問題
過去幾年,圍繞 LLM 的工程實踐出現了幾個高頻詞彙:Prompt Engineering、Context Engineering、Harness Engineering。它們聽起來都是「讓 AI 跑得更好」,但實際上在解決三個完全不同層次的問題:
| 領域 | 核心問題 |
|---|---|
| Prompt Engineering | 怎麼說,才能得到最好的輸出? |
| Context Engineering | 什麼信息,應該在什麼時候進入 context window? |
| Harness Engineering | 怎麼建立一套系統,讓模型能安全、可控地在真實世界行動? |
這三個問題不是競爭關係,而是不同抽象層次的工程問題。弄清楚它們各自在解決什麼,是這篇文章的起點。
Prompt Engineering — 最早被認識的那個
Prompt Engineering 關注的是單次訊息的輸入輸出品質:同樣的模型、同樣的信息,怎麼問才能得到最好的答案?
典型技術包括 few-shot 示範、chain-of-thought 推理、system prompt 設計、XML tag 格式控制等。它最有效的場景是「模型能力本身夠,只是沒被正確引導」。
但 Prompt Engineering 有一個清晰的邊界:它只能影響「怎麼說」,不能改變「模型能做什麼」,也不能解決跨 session 的連貫性問題。當任務從「生成一段文字」變成「完成一個複雜的多步驟任務」,單靠 prompt 設計是不夠的。
Context Engineering — 新興的那個
Context Engineering 是 Andrej Karpathy 在 2025 年提出的概念,定義是「the art of filling the context window with just the right information at just the right time」。
它關注的是信息供給:RAG 把外部知識拉進來、memory retrieval 把跨 session 的記憶注入、chunking 和 context pruning 決定哪些信息值得保留。最有效的場景是「模型能力夠、prompt 也對,但因為沒看到對的信息而輸出差」。
Context Engineering 和 Harness Engineering 之間有一塊灰色地帶:上下文管理(壓縮、注入、清理)到底屬於哪個?一個相對清晰的劃分方式是——信息決策(選什麼)屬於 Context Engineering,執行機制(怎麼做到)屬於 Harness Engineering。但在實作中,兩者高度耦合。
Harness Engineering — 這篇的主角
比喻:馬術的 Harness
Harness 這個詞來自馬術——韁繩、馬鞍、轡頭的總稱。它不改變馬的能力,但決定:
- 馬能往哪個方向走
- 走多快、走多遠
- 出了問題怎麼拉回來
對 AI 系統來說,模型是馬,harness 是讓牠能被安全騎乘的整套裝備。Harness Engineering 關注的是圍繞模型建立的執行基礎設施——不是模型架構本身,而是那套讓模型能在真實世界中安全行動的系統。
從「文字工具」到「執行代理」
理解 Harness Engineering 的必要性,需要先理解一個轉變:AI 模型從「文字生成工具」變成了「執行代理」。
當模型只是輸出文字時,最壞的情況是答案不好——你重新問一次就行了。Prompt Engineering 就夠應付這個場景。
但當模型開始執行操作——讀寫檔案、呼叫外部 API、啟動子任務、修改資料庫——情況就不一樣了:
操作有副作用,不可逆。 刪了的檔案、送出的 API 請求、提交的 git commit,不是改個 prompt 就能還原的。你需要一套機制在操作發生前做判斷,在出問題時能攔截。
任務有狀態,跨越多個輪次。 一個真實的 coding 任務可能需要幾十輪對話:探索 codebase、修改程式碼、執行測試、根據結果調整。模型在每一輪都是「無記憶」的,需要 harness 負責把狀態帶過去。
系統有成本,資源不是無限的。 Context window 有上限,API 呼叫有費用,長時間運行的任務會累積大量的歷史。需要 harness 來管理這些消耗,避免系統在高負載下失控。
複雜任務需要多個代理協作。 單一 LLM 的注意力和 context 有限。並行探索多個方向、分工驗證、規劃與執行分離——這些需要一套 harness 來協調多個 agent 的工作。
這四個問題,任何一個都不是「寫更好的 prompt」能解決的。
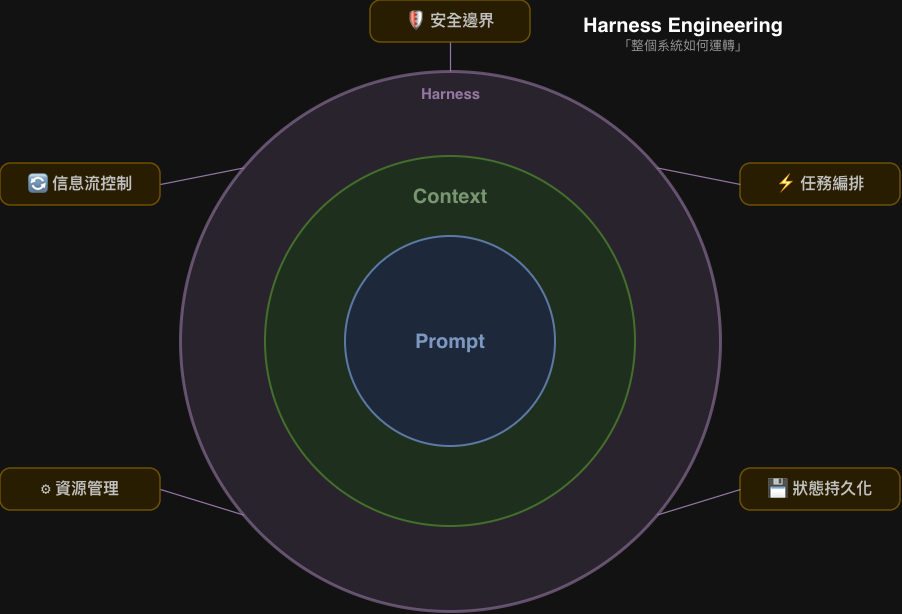
Harness 的五個維度
| 維度 | 負責什麼 |
|---|---|
| 資源管理 | Token 預算、成本控制、熔斷機制——防止系統失控消耗 |
| 狀態持久化 | Memory 系統——讓 stateless 模型在有狀態的世界中工作 |
| 信息流控制 | Context 壓縮、雙視圖——決定模型每輪「看到什麼」 |
| 安全邊界 | 工具權限、行為約束——讓能力強但副作用可控 |
| 任務編排 | Multi-agent 協調——超越單一 LLM 的工作上限 |
三者的關係:不同層次,互相補充
Harness Engineering(系統層)
└── Context Engineering(信息層)
└── Prompt Engineering(訊息層)
這三個層次在不同規模的任務下有不同的重要性:
- 只需要 Prompt Engineering:一次性的翻譯、文案生成、簡單問答
- Prompt + Context:需要參考外部知識的問答系統、文件搜索助手
- 三層都需要:production AI agent,長時間運行、有工具、有記憶、有多步驟任務
一個常見的誤解是認為三者是遞進關係——先把 prompt 做好,再做 context,再做 harness。實際上,當你決定要建一個「執行代理」而不是「問答系統」的那一刻,harness 的設計就應該和 prompt 一起進入考量。
工程師角色的轉變
Harness Engineering 不只是一個技術問題,它正在改變工程師的工作方式。
OpenAI 和 Anthropic 的實踐都指向同一個方向:工程師的工作正在分成兩塊截然不同的事情。
第一塊:設計環境。 當 Agent 卡住時,不再是「Agent 出了什麼問題」,而是「環境缺少了什麼讓 Agent 無法繼續」。焦點從實作轉向賦能——診斷 Agent 需要什麼工具、什麼信息、什麼約束才能可靠地完成任務。
在這塊工作裡,規劃的優先級遠高於執行。Cloudflare 工程師 Boris Tane 把這個原則說得很直接:
> 「永遠不要讓 Agent 在你審查和批准書面計劃之前寫代碼。規劃與執行的分離是我做的最重要的一件事。」
Agent 一旦開始執行,中途糾偏的成本比人類寫代碼時更高——它可能已經修改了多個文件、建立了多個前提假設。在開始前讓 Agent 生成一份計劃,讓你審查後再開始,能避免大量的重工。
第二塊:管理工作。 當多個 Agent 並行運行,工程師的角色更像一個管理者——分配任務、觀察進度、在 Agent 偏離時重定向。Stripe、Cloudflare 等團隊的工程師同時管理 5-10 個 Agent 並行工作已經是常態。
這種工作模式在成熟度上分成兩種:
| 模式 | 描述 | 前提條件 |
|---|---|---|
| 有人值守並行 | 主動監管多個 Agent,即時檢查、按需重定向 | 認知負擔高,但 harness 不需要很成熟 |
| 無人值守並行 | 發佈任務後離開,Agent 自主完成到 PR | harness 必須足夠成熟才能信任 Agent |
Stripe 能做到無人值守並行,是因為他們已建立了完整的預暖開發環境和 CI 整合。大多數團隊目前還在有人值守的階段。一個團隊在這個光譜上的位置,取決於 harness 的成熟度——不是模型能力。
這兩塊不是順序關係,而是相互影響的回饋循環:Agent 的失敗告訴你環境缺少什麼;更好的環境讓管理更順暢。
業界趨勢:Harness 走向何方
Harness 將成為服務模板
Martin Fowler 提出了一個有趣的預判:大多數組織只有兩三個主要技術棧。未來,團隊可能從一組預製 Harness 中選擇,就像今天的 Service Template 幫助團隊在「黃金路徑」上啟動新服務。
一個完整的 Harness 模板可能包含:自定義 linter 規則、結構測試、基礎 context 和知識文件、額外的 context 提供者、預配置的 CI/CD 管道。
越做越薄,而不是越做越複雜
Manus 團隊在半年內重寫了五次 Harness,但每次的方向都是簡化,而不是加複雜度——用通用 shell 執行替代複雜工具定義,用結構化交接替代管理 Agent,採用 Agent-as-a-Tool 模式。
這個方向和 Managed Agents 的出現互相呼應。Anthropic 的 Claude Managed Agents 把 Session 持久化、Sandbox 隔離、水平擴展、TTFT 優化這類「管線問題」(plumbing)從 harness 裡分離出去,交給平台負責。它不解決「這個 Agent 要做什麼」——你的 tools 怎麼設計、system prompt 怎麼寫、任務怎麼拆解、domain-specific 的錯誤怎麼處理,這些仍然是你的責任。
這正是「越做越薄」的具體體現:把能委託給平台的 infra 問題全部委託出去,讓 harness 只保留無法被通用化的 domain 知識。Managed Agents 不是讓 Harness Engineering 消失,而是讓它升維——從「怎麼讓 Agent 不掛掉」升級到「怎麼讓 Agent 在你的業務場景裡做對的事」。
隨著模型能力提升,harness 應該越做越薄。如果發現 harness 越做越複雜,大概率是過度工程化——在用基礎設施補償本來可以直接信任模型的地方。過度客製化的機制,遲早會成為模型演進的枷鎖。
更強的模型讓 Harness 更重要,不是更不重要
一個常見的誤解是「模型越強,harness 就越不需要了」。實際情況相反。
研究者 Nicholas Carlini 的 C 編譯器項目給了直接的證據:Opus 4.5 能產出可用的編譯器,Opus 4.6 能編譯 Linux 內核——但每個能力級別都需要重新設計 harness。模型越強,能給的自主權越大,護欄就需要越精準。不是更少 harness,而是更好的 harness。
給工程師的 Takeaway
如果你在用 LangChain、LangGraph 或自己的框架搭建一個 AI agent,這五個維度是一份不錯的檢查清單:
- 資源管理做了嗎? 你的 context 滿了之後怎麼辦?有沒有熔斷機制防止無限循環消耗?
- 狀態持久化做了嗎? 跨 session 的知識存在哪?怎麼讀回來?有沒有機制判斷哪些值得存?
- 信息流控制做了嗎? 每一輪送給模型的 context 是精心選擇的,還是把所有東西都塞進去?
- 安全邊界做了嗎? 模型能呼叫的工具有沒有約束?危險操作有沒有攔截和確認機制?
- 任務編排需要嗎? 你的任務複雜到需要多個 agent 協作嗎?如果需要,通信和權限怎麼設計?
這五個問題,任何一個沒想清楚,都可能成為系統在 production 環境下的瓶頸。
延伸閱讀
- 用 LangChain + LangGraph 實作 Harness Engineering:從 deepagents 學到的設計模式 — 下一篇:把 Harness 五個維度用 LangChain + LangGraph 實際落地的 POC
- 打開原始碼才發現:三個 Agent 框架,三種截然不同的設計哲學 — 從原始碼看 Harness:deepagents、openclaw、hermes 各自怎麼實作這五個維度
- Harness Engineering 的地基:LLM Session 設計框架 — Harness 的最底層:session 設計如何決定整個 Agent 系統能不能存活