Frontier、Mini、還是自建:Production LLM 的架構沒有標準答案
最近在做 System Design 的時候,一直繞著同一個問題打轉:同樣是「讓系統能用 LLM」,到底要選哪條路?
Frontier model 直接上最省事,但 cost 和 latency 是問題。Mini model 是個中間地帶,但它解決的是成本問題,不見得解決能力問題。自建 HuggingFace model 有最多的控制權,但工程複雜度的代價也是真實的。
這三個選擇放在一起,邊界其實很難畫。這篇沒有標準答案,是想整理一下我的思考,然後問問大家實務上怎麼看。
一個假設:這三個選擇是一條路,不是三個平行選項
在想這件事的過程中,逐漸形成了一個假設:
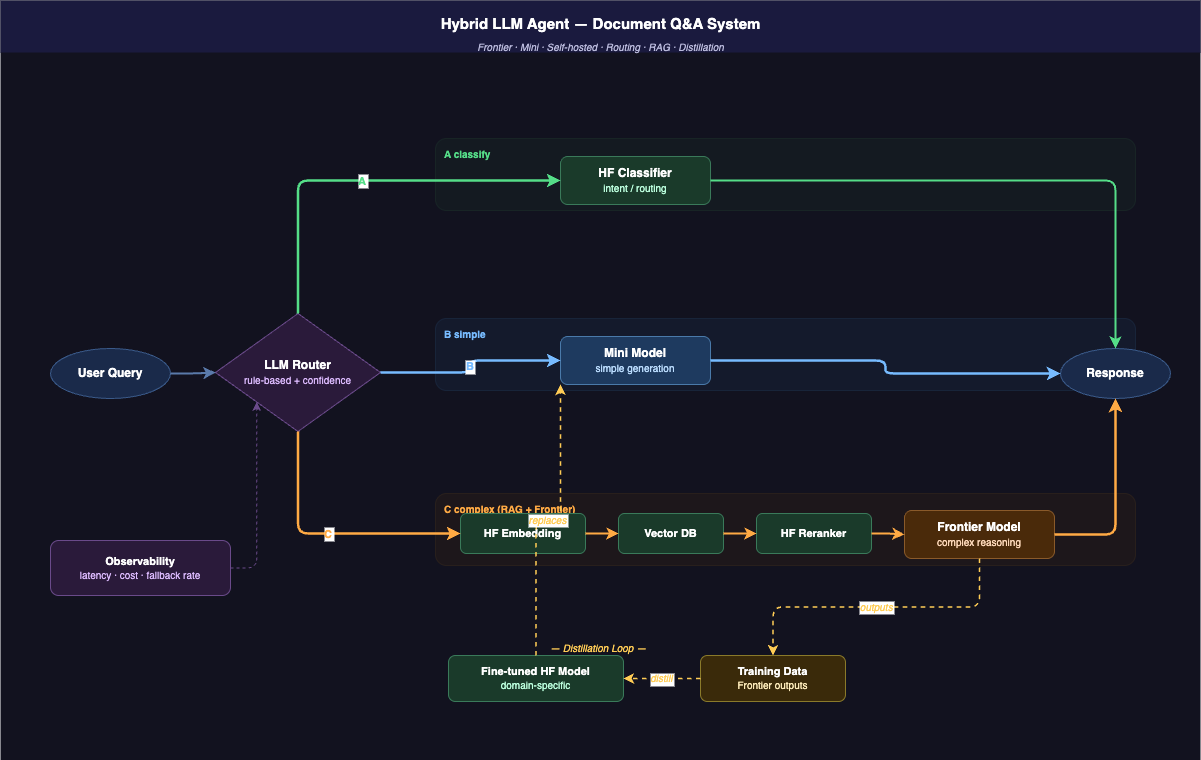
Frontier model → Mini model → 自建模型,這不只是一個成本遞減的序列,而是一條「從快速驗證到逐漸掌控」的演化路徑。每個階段在學的東西不一樣,學夠了才有條件走到下一步。
Frontier 階段:在學這個問題本身。 這個任務能不能被 LLM 解?失敗的邊界在哪?哪些 case 特別難?用最強的 model 先跑通,不是因為它最終會留下來,而是不想讓「model 不夠強」這個變數干擾對問題的理解。觸發往下走的信號可能是:failure mode 已經摸清,而且 cost 開始有感。
Mini 階段:在學 model 的邊界。 方向確認了,開始降規,回答「Frontier 能做到的,Mini 差在哪裡?」有些任務幾乎無感,有些會出現明顯的品質下降——這個摸索本身很有價值,它讓你分清楚哪些任務真的需要強推理,哪些其實只是 pattern matching。觸發往下走的信號:有足夠的 labeled data,而且清楚通用模型在這個 domain 裡補不起來的地方。
自建階段:在掌控整條鏈。 Fine-tuning 用自己的資料,embedding 針對 domain 調整,甚至可以用 Frontier 的輸出當訓練資料來蒸餾更小、更精準的模型。這個循環讓「自建」不是從零開始,而是站在之前每個階段累積的理解上。
這只是我的一個想法,不確定是不是普遍成立。有些場景從第一天就只能自建(隱私合規),有些可能永遠不需要走到自建。但比起問「哪個比較好」,問「現在在哪個階段」感覺更接近實際做決策的方式。
有在 production 上走過這條路的人,實際經驗是這樣嗎?
成本:不只是帳單的問題
cost 通常是讓人開始認真考慮這個問題的第一個壓力,但我發現它比想像中複雜。
自建省下的不只是 API 費用,GPU infra、維護工程師的時間、模型品質下降的 downstream 影響都要算進去。所以「自建比較省」這件事,大概要在特定 volume 和任務複雜度下才真的成立,threshold 每個系統都不一樣。
另一個我在想的問題是:如果一開始就為了省錢設計了一套完整的 Hybrid 架構,但後來發現實際流量根本沒那麼高,或者等系統準備好的時候,市場上已經有了更便宜的開源解法——那個精心設計的成本優化,解決的可能是一個當初還不存在的問題。
所以我有個猜想:cost 優化的時機可能比選擇本身更重要。等到 solution 被驗證、cost 真的成為壓力,再來動架構,也許比一開始就設計完美更務實。不確定這個想法在實際場景下成不成立,也許不同規模的團隊答案差很多。
Domain 特殊性:通用模型的邊界在哪?
通用模型在 general task 上越來越強,但問題是你的任務有多 general?
有幾個地方我覺得自建的優勢比較結構性,不只是成本:
Embedding 和 reranking:RAG pipeline 裡這兩個步驟對 domain-specific 的語料很敏感,通用 embedding 在特定 domain 裡的效果可能比預期差。
Fine-tuning 的自由度:Mini model 可以 fine-tune,但在 vendor 的框架裡。HuggingFace 的模型可以從資料到訓練流程完全掌控,當 domain 很特殊的時候,這個差距會放大。
知識蒸餾:用 Frontier model 的輸出當訓練資料,蒸餾出 domain-specific 的小模型——這個循環讓自建不是從零開始的苦差事。
隱私與合規:有些 Slot 從一開始就決定了
有些場景不是 trade-off,是約束。
payload 裡有 PII、醫療資料、或合規限制的場景,external API 直接出局,起點就是自建或 on-prem。有趣的是,這類場景反而可能更早積累 domain-specific 的資料和能力,因為沒有「先用 API 驗證」這個選項。
Hybrid 的現實:Routing 本身也是個問題
如果系統同時用了多個 model,routing 邏輯就是下一個要面對的問題。
Rule-based routing 簡單可預測,但容易長成一堆 if-else。Model-based routing(用 confidence score 決定 fallback)看起來更優雅,但多了一層 latency 和一個新的失敗點。而且不管哪種,沒有 observability 的話很難知道 routing 有沒有在正確運作——每個 model 的 latency、cost、error rate、fallback 頻率,這些缺了就是個黑盒。
Hybrid 是一個合理的方向,但複雜度很容易被低估。這大概是另一個值得單獨討論的題目。
最後
以上都是從 System Design 角度想到的問題,沒有實際踩坑的經驗支撐。如果你有在 production 上做過類似的決策,很歡迎分享你的經驗——不管是走過哪條路、遇過什麼問題,或者覺得這篇哪裡想得不對,都很想聽聽看。
Hybrid 大概是個合理的終態,但「要怎麼 Hybrid」才是真正的工程問題。
延伸閱讀
- Langfuse — 模型選型之後:用 Langfuse 監控不同模型的 latency、cost、error rate,才能驗證選型決策
- LLM Cache 策略:從 Prompt Cache 到 Semantic Cache — 降成本的互補方案:Frontier model + cache,比直接換 mini model 更靈活
- 你的 Prompt 為什麼有效:從 Transformer 機制看 AI 系統設計 — 模型選型的底層邏輯:Transformer 架構決定了 context window、latency、能力邊界