Dynamic Cheatsheet Paper 筆記
核心問題
如何讓 LLM Agent 在推理(Inference)階段也能夠持續學習,使其表現隨著推理次數增加而逐步提升?
傳統的機器學習模型在訓練完成後就固定不變,但 Dynamic Cheatsheet 提出了一種創新方法,讓模型在實際使用過程中也能累積經驗並自我優化。
論文連結:Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory
技術架構
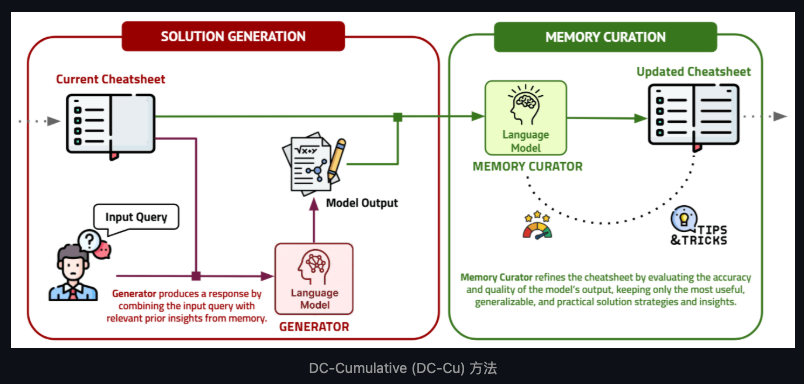
Dynamic Cheatsheet 框架由三個核心模組組成,協同運作以實現推理階段的持續學習:
1. 動態速查表記憶體(DC Memory)
用於儲存模型在推理過程中自動識別出的有效策略、程式碼片段與解題洞見。
特點:
- 動態擴充與精簡:記憶體內容可隨任務進行調整
- 高可轉移性:儲存的知識片段可應用於類似任務
- 精煉性:保留最有價值的洞見,避免冗餘
2. 自我策展機制(Self-curation Engine)
負責在推理階段自動篩選、抽取並整理可重用的知識片段,完全無需人類介入。
功能:
- 自動識別有效的解題模式
- 過濾低品質或無關的經驗
- 保持速查表內容的高質量與高相關性
- 防止語境膨脹(Context Bloat)
3. 推理階段記憶調用模組(Inference-time Retrieval)
在每次推理時,根據任務需求動態調用速查表內容,輔助模型生成更準確的解題步驟或答案。
優勢:
- 即時能力強化
- 任務導向的知識檢索
- 提升推理準確性與效率
關鍵發現(Key Findings)
透過實驗驗證,研究團隊發現了一個重要現象:
單純保留過去經驗的方法效果有限:將所有過去的輸入輸出範例(Input-Output Examples)直接放入 LLM 的輸入情境中的方法(Full History, FH),不僅無法顯著提升表現,有時甚至比完全不使用這些經驗、單純用 Prompt 驅動 LLM 的基準方法(Baseline, BL)來得更差。
為什麼會這樣?
- 資訊過載:大量未經篩選的經驗會造成情境污染
- 缺乏相關性:不是所有過去經驗都與當前任務相關
- 噪音干擾:低品質的經驗可能誤導模型推理
解決方案的重要性
這個發現凸顯了 DC-RS(Dynamic Cheatsheet with Retrieval and Self-curation)方法中兩個關鍵機制的重要性:
- Retrieval(檢索):只取出真正相似且相關的過去經驗
- Curation(策展):將這些經驗精煉成更簡潔、更泛化的洞見(Insights)
核心洞察(Summary)
單純地將所有資訊放入 Memory 或從 Memory 中取出所有資訊,所帶來的表現提升是非常有限的。
真正有效的記憶管理需要:
✅ 智能檢索(Memory Retrieval):根據任務相似度選擇性提取相關經驗\
✅ 內容策展(Curation):將原始經驗提煉為可重用的知識片段\
✅ 動態更新:持續優化記憶體內容,淘汰過時或低效的資訊
這三者缺一不可,才能實現高效率的推理階段學習與表現提升。
延伸閱讀
- ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory — 相近問題的另一個解:推理記憶的跨任務遷移設計
- Agentic Context Engineering:讓 AI 代理人自我改進的關鍵技術 — 系統性框架:動態備忘錄只是 context engineering 的一個工具
- hermes-agent:從原始碼看一個為 Production 設計的 Agent 系統 — 實際系統如何在 production 裡實作 context 壓縮與記憶管理