在 Claude Code 的年代,我為什麼還要學 C++?
系列:C++ AI 推論 10 天學習筆記 — Day 1
這不是一篇語法教學,而是一個 Python/Go 工程師試圖搞清楚:「C++ 在現代 AI 工程裡的位置到底是什麼?」的探索過程。
一個讓我困惑的現象
最近在研究幾個 LLM serving 框架,發現一件有趣的事:
vLLM、TensorRT-LLM、llama.cpp、Flash Attention——這些 Python 工程師每天在用的工具,底層幾乎全是 C++。
我第一個反應是:為什麼?
Python 有 sentence_transformers、transformers、onnxruntime,連 CUDA 推論都只要幾行就能搞定。vLLM 可以直接部署 LLM。現在又有 Claude Code 幫你寫 code——在這個年代,這些框架為什麼還要用 C++ 寫核心?
這個問題讓我開始研究,最後的發現改變了我對「學習 C++」這件事的看法。
先問一個更根本的問題:Python 的套件夠快嗎?
比如說,我用 sentence-transformers 做 text embedding,底層呼叫的是 ONNX Runtime,而 ONNX Runtime 的矩陣乘法是高度優化的 C++ 代碼。那 Python 的 wrapper 到底慢在哪?
讓我們看一次完整的推論請求,從文字進來到 embedding 出去,中間發生了什麼:
[原始文字]
│
▼
① Tokenization(文字 → token id)
│
▼
② 把資料搬到 GPU(H2D)
│
▼
③ 模型前向傳播(Transformer 矩陣乘法) ← ONNX Runtime 負責這步
│
▼
④ 把結果搬回 CPU(D2H)
│
▼
⑤ 後處理(normalize、cosine similarity)
│
▼
[Embedding Vector]
關鍵洞察:ONNX Runtime 只負責步驟 ③。 其他步驟都是 Python 在做。
在生產環境的實測中,對 all-MiniLM-L6-v2(一個 22M 參數的小模型)做 profiling,breakdown 大概是這樣:
Tokenization: 2.1ms (48%)
H2D transfer: 0.8ms (18%)
Inference: 1.3ms (30%) ← 以為最重要的,反而不是最大
D2H transfer: 0.2ms (4%)
Total: 4.4ms
推論本身只佔 30%。 搬資料和前處理佔了剩下的 70%。
這就是 C++ 發揮作用的地方。不是讓矩陣乘法變快(ONNX Runtime 已經把這件事做得很好了),而是讓矩陣乘法以外的所有事更有效率。
用一個比喻:ONNX Runtime 是廚師,Python/C++ 是服務生。廚師的速度沒差,差的是服務生的效率——有沒有預分配好盤子(zero allocation)、端菜途中換了幾次容器(記憶體複製次數)、能不能同時備料和出菜(CPU/GPU 並行)。
但這還不是全部
如果只是 embedding service 的優化,這個故事還算簡單。真正讓 C++ 在 AI 工程裡不可取代的,是這些場景:
LLM Inference 的核心是 C++
你在用的每一個 LLM serving 工具,底層都是 C++:
- llama.cpp:讓 LLM 在 CPU 跑成為可能,整個專案是 C/C++
- vLLM:Python 是 orchestration 層,真正的 GPU kernel 是 C++ CUDA
- TensorRT-LLM:NVIDIA 的 LLM 推論庫,全是 C++
- Flash Attention:重新實作 attention 機制的 CUDA kernel,不是 Python 能寫的
當你需要讓 KV cache 更有效率、讓 attention 的記憶體存取更好、或是為特定硬體定製推論邏輯——這些都是 C++ 的領域。
Tokenizer 也是 C++
Hugging Face 的 tokenizers 套件,Python 只是 wrapper,核心是用 Rust(效能語言)寫的。為什麼?因為對一百萬個文字做 tokenization 的速度,用 Python 和用 Rust/C++ 差了一個數量級。
Custom Operator
有時候 ONNX 不支援你的模型的某個 op,或內建的 op 效率太差。這時候你需要寫 custom CUDA kernel——一個 Python 完全做不到的事。
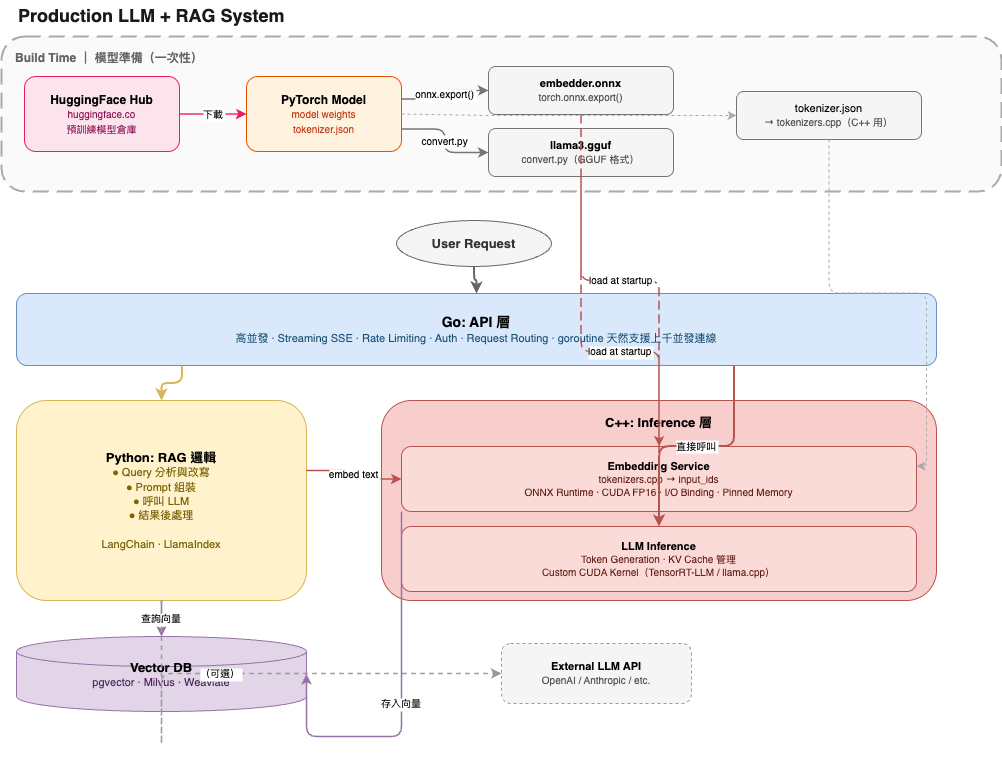
一個完整的生產 LLM 服務長什麼樣
這裡有個我覺得最重要的思維轉換:沒有人只用一種語言建生產 AI 服務。
而且,整個系統分成兩個截然不同的時間點:Build Time(模型準備階段)和 Runtime(服務上線後)。
先搞清楚:HuggingFace 在哪裡?
很多人第一次看 C++ 推論 code 時都會問:「為什麼沒有 from transformers import ...?」
原因是:HuggingFace + PyTorch 是 Build Time 工具,不是 Runtime 工具。
【Build Time:一次性準備,不在服務熱路徑上】
HuggingFace Hub
│
│ $ huggingface-cli download sentence-transformers/all-MiniLM-L6-v2
▼
PyTorch Model(.bin / .safetensors)
│
├─── $ python export.py ──────────────► embedder.onnx
│ torch.onnx.export(model, ...) (給 ONNX Runtime 用)
│
└─── $ python convert.py ────────────► llama3.gguf
llama.cpp/convert_hf_to_gguf.py (給 llama.cpp 用)
+ tokenizer.json(直接複製)
【Runtime:每次請求都會跑到】
C++ Inference Service
├── 啟動時載入: embedder.onnx → ONNX Runtime Session
├── 啟動時載入: llama3.gguf → llama_load_model_from_file()
└── 啟動時載入: tokenizer.json → tokenizers.cpp
關鍵洞察:「先存下來,再用 C++ 跑」。
PyTorch 的 .bin 格式太大、帶了很多訓練用的 metadata、而且只能用 Python 讀取。
onnx.export()把模型轉成跨平台的推論格式(移除 training graph、凍結權重)convert_hf_to_gguf.py把模型量化成 llama.cpp 能直接 mmap 的格式
這樣 C++ Runtime 就完全不需要依賴 Python 或 HuggingFace 的任何套件。 啟動時 mmap 模型檔案(零複製載入),之後每個 request 都在純 C++ 裡跑。
完整的生產架構
以一個典型的 LLM + RAG 系統為例:
每一層的選擇都有理由:
| 層 | 工具 / 語言 | 時間點 | 為什麼這個選擇 |
|---|---|---|---|
| 模型來源 | HuggingFace Hub | Build Time | 最大的預訓練模型庫,一行下載 |
| 模型轉換 | PyTorch + onnx.export() | Build Time | 從訓練格式轉成推論格式,移除 training graph |
| 量化轉換 | llama.cpp convert.py | Build Time | 壓縮 LLM 至 GGUF,支援 CPU mmap 載入 |
| API / 路由 | Go | Runtime | goroutine 天然高並發,streaming 簡單,binary 部署方便 |
| RAG 邏輯 / 流程 | Python | Runtime | 生態最豐富(LangChain、LlamaIndex),迭代最快 |
| Embedding 推論 | C++ (ONNX Runtime) | Runtime | 高頻呼叫,latency 嚴格,需要 GPU 精細控制 |
| LLM 推論(本地) | C++ (llama.cpp / TensorRT) | Runtime | KV cache 管理、custom CUDA kernel、streaming |
| Tokenization | tokenizers.cpp (Rust) | Runtime | Python tokenizer 比 Rust 慢 10x,高頻路徑不能用 Python |
| 資料存儲 | PostgreSQL + pgvector | Runtime | 向量搜尋和一般查詢在同一個 DB |
這不是「哪個語言最好」的問題,而是每個工具在它設計的時間點和位置做它最擅長的事。
HuggingFace + PyTorch 在 Build Time 提供了完整的模型生態;C++ 在 Runtime 提供了極致的效能。兩者不是競爭關係,而是流水線的前後段。
那麼,Claude Code 寫 code 的年代,我還需要學 C++ 嗎?
這才是我最想說的部分。
我可以請 Claude Code 寫 C++ code。實際上本系列後面的大量代碼都是在 AI 輔助下完成的。手寫 C++ 已經不是學習目標了。
但我在過程中發現,「能不能用好 AI 寫 C++」取決於你是否具備以下能力:
1. 技術選型判斷:知道什麼時候需要 C++
如果你不知道 Python embedding service 的瓶頸在 GIL 和記憶體複製,你就不會想到「這裡需要 C++」。AI 沒辦法替你做這個判斷——或者說,你沒有辦法提出正確的問題。
2. 清楚表達優化目標
「幫我用 C++ 優化推論」是一個很爛的 prompt。 「我需要用 C++ 實作一個 text embedding service,使用 ONNX Runtime CUDA EP,用 I/O Binding 避免 D2H 複製,用 Pinned Memory 加速 H2D,目標是把 latency 從 4ms 降到 1ms」——這才是有效的 prompt。
差距在於:你需要知道優化技術的名字和目標,才能告訴 AI 要做什麼。
3. 驗證 AI 的輸出
AI 生成的 C++ code 不一定是對的。它可能:
- 在 GPU 推論後忘了
cudaDeviceSynchronize(),導致計時結果錯誤 - 把
unique_ptr複製而不是移動,導致編譯錯誤 - 用了
session.Run()的方式不適合 I/O Binding 的場景
你需要讀懂代碼,才能發現問題。而讀懂代碼需要的門檻,比自己寫代碼低得多。
4. 知道「對」的樣子
你需要知道一個 latency breakdown 的正常數字是多少,I/O Binding 之後 H2D 應該降到什麼程度,pinned memory 帶來的提升應該是幾倍——不然你沒辦法判斷 AI 給你的方案有沒有達到目標。
所以這個系列在學什麼
這個系列不是 C++ 語法教程。是這樣的:
- 建立推論 pipeline 的心智模型:知道一個 embedding request 的每一毫秒花在哪裡
- 學會看數字:benchmark、latency breakdown、QPS——優化的依據
- 認識優化技術的名稱和概念:I/O Binding、Pinned Memory、CUDA Streams、FP16 量化——這樣才能跟 AI 溝通
- 理解 Python/Go/C++ 在完整系統裡的分工:做出對的技術選型
最終目標:面對一個 AI 系統的設計需求,能判斷哪些部分應該用 Python,哪些用 Go,哪些需要 C++,以及為什麼。
這個系列在做什麼
這是一份學習筆記,以 text embedding pipeline 作為主線,用 HuggingFace 的預訓練模型,在 M2 Mac 本機上跑出實際數字。
起點是 Python sentence-transformers 的開箱即用寫法。終點是 C++ 加上 ONNX Runtime,並透過 CoreML Execution Provider 跑在 Apple Silicon 的 Neural Engine 上——不需要雲端 GPU,全程本機可驗證。
最後的成績單大概長這樣(M2 Mac 實測,all-MiniLM-L6-v2):
| 版本 | Latency | vs Python |
|---|---|---|
Python sentence-transformers | ~20ms | 1x |
| C++ ONNX Runtime(CPU FP32) | ~5ms | ~4x |
| C++ ONNX Runtime(CoreML EP) | ~1-2ms | ~10-20x |
每一步都有可以在本機跑的數字,每一步都知道做了什麼、為什麼有效。
這才是我想要的學習方式。
關於這個系列的寫作方式
本系列大量使用 AI 輔助(Claude Code)生成代碼,我負責架構設計、優化目標設定和結果驗證。 這本身就是我認為正確的 C++ 學習方式:不是背語法,而是知道要做什麼、能判斷做得對不對。
延伸閱讀
- 給 Python/Go 工程師的 C++ 語法地圖:推論篇 — 系列 Day 2:有了目標後,7 個真正需要懂的 C++ 語法概念
- 不靠直覺,靠實驗:用 AutoResearch 找到 C++ 的 33x 優化空間 — 系列 Day 3:用 AutoResearch 讓 Agent 自己找到 33x 的優化空間
- 你的 Prompt 為什麼有效:從 Transformer 機制看 AI 系統設計 — 從 Transformer 機制到推論引擎的連結:為什麼 C++ 是 AI inference 的核心