AI 自主研究實驗:讓 Agent 在你睡覺時跑 100 個實驗

引言
大家都知道 AI 已經會寫 ML 程式碼了,但有個問題一直沒解決:
實驗還是要人類一個一個跑。
能不能讓 AI 自己做實驗?
最近 Karpathy 發布的 autoresearch 很夯:
> “給 AI Agent 一個小型 LLM 訓練環境,讓它自主實驗一整晚。它會改 code、訓練 5 分鐘、檢查結果、決定 keep 或 discard,然後重複。你早上醒來,看到 100 個實驗的 log。”
核心設計很特別,只有三個檔案:
| 檔案 | 誰修改 | 作用 |
|---|---|---|
prepare.py | ❌ 不修改 | 固定基礎設施 |
train.py | 🤖 AI Agent | 模型、optimizer、訓練 loop |
program.md | 👤 人類 | Agent 的行為指令 |
program.md 是「研究組織的 code」:
LOOP FOREVER:
1. Hack train.py
2. git commit
3. Run experiment
4. Check val_bpb
5. Keep if improved, discard if worse
6. Repeat
**NEVER STOP**: The human might be asleep.
思維轉變:從「做決策」到「設計決策流程」
| 階段 | 人類做什麼 | AI 做什麼 |
|---|---|---|
| 2.0 | 做決策 | 寫 code |
| 3.0 | 設計決策流程 | 做決策 + 寫 code |
從「人類研究者」變成「研究流程設計師」。
這篇文章在講什麼?
我把 autoresearch 從 LLM pretraining 改成 Titanic 生存預測,跑了幾天實驗。
這篇文章分享:
- 為什麼選 Titanic?改了什麼?
- 5 個實驗的詳細過程(30 秒/實驗,找到 +1.12% 改善)
- 如何客製化
program.md(多指標、過擬合檢查、時間預算) - 我踩過的 5 個坑
- 從中學到的洞察
風格:直白、簡單、像實戰筆記。
準備好了嗎?開始吧。
Chapter 1:program.md 的原始設計 — 研究組織的 code
在講我的實驗之前,先快速說明 autoresearch 的核心設計。
三個檔案,三種角色
autoresearch 只有三個關鍵檔案:
| 檔案 | 誰修改 | 作用 |
|---|---|---|
prepare.py | ❌ 不修改 | 固定基礎設施(資料、評估函數) |
train.py | 🤖 AI Agent | 模型、optimizer、訓練 loop |
program.md | 👤 人類 | Agent 的行為指令 |
核心邏輯:
prepare.py固定評估標準(不能作弊)train.py是 Agent 唯一能改的檔案(所有實驗都是改它)program.md定義 Agent「怎麼做研究」
program.md:The Experiment Loop
原版的核心循環:
LOOP FOREVER:
1. Modify train.py with an idea
2. git commit
3. Run experiment (fixed 5 minutes)
4. Check val_bpb
5. If improved → keep commit
6. If worse → git reset (discard)
7. Repeat
**NEVER STOP**: The human might be asleep.
這不是文件,這是程式碼。
Agent 會 literally 執行每一步:
- 改 code → 跑實驗 → 看結果 → 決定 keep/discard → 重複
你睡覺時,Agent 跑 10 個實驗(~12/小時),自己決定哪些 keep。
為什麼這個設計聰明?
1. 固定時間預算 = 公平比較
- 不管模型多大,都是 5 分鐘
- 小模型跑更多 steps,大模型跑更少 steps
- 逼 Agent 平衡「模型容量」和「訓練效率」
2. 單一指標 = 明確目標
- val_bpb 越低越好(沒有歧義)
- Agent 不用判斷「accuracy 高但 precision 低算不算好」
3. Git-based = 自動版本控制
- Keep → commit 保留
- Discard → git reset 回滾
- 所有實驗歷史都在 git log
4. NEVER STOP = 真正自主
- 不會問「要繼續嗎?」
- 你睡覺,Agent 工作(8 小時 = ~100 實驗)
5. Simplicity Criterion = 避免過度優化
+0.001 改善但加 20 行複雜 code?不值得。
-0.001 但刪掉 code?更好。
小結
理解原版設計的關鍵:
- 三個檔案的分工(固定 / Agent 改 / 人類設計)
- The Loop(改 code → 跑實驗 → keep/discard → 重複)
- 核心規則(固定時間、單一指標、git-based、NEVER STOP)
接下來講我如何把它改成 Titanic 實驗,以及客製化了什麼。
Chapter 2:為什麼選 Kaggle Titanic?
問題:我沒有 H100
看到 autoresearch 後,我第一個反應是:「試試看!」
然後發現:原版需要 NVIDIA H100 GPU 來跑 LLM pretraining。
我只有 MacBook Pro(Apple Silicon)。
核心問題:能不能用在其他 ML 任務?
autoresearch 的預設場景是 LLM pretraining,但核心概念(固定時間 + Agent 自主實驗 + git-based workflow)應該適用於其他任務。
我想測試的問題:
- autoresearch 能不能用在「一般 ML 任務」?
- 小數據集 + 簡單模型行不行?
- MacBook 能不能跑?
為什麼選 Titanic?
我需要一個「大家都熟悉」的問題,原因:
1. 耳熟能詳
- Kaggle 最經典的入門題
- 大家都知道是什麼任務(生存預測)
- 有共同語言,容易理解實驗結果
2. 小而快
- 891 個樣本,18 個特徵
- 30 秒就能訓練一個模型
- 適合快速迭代(不用等 5 分鐘)
3. 有 ground truth
- Kaggle leaderboard 可以驗證
- 知道「好模型」大概什麼水準(~85-87%)
- 不會迷失在「這個結果到底好不好」
4. MacBook 能跑
- 用 MLX(Apple Silicon 的 ML 框架)
- 不需要 NVIDIA GPU
類比:就像學程式要先寫 Hello World,測試 autoresearch 也該選最熟悉的問題。
我改了什麼?
核心改動只有三個檔案:
1. prepare_titanic.py(替換 prepare.py)
- 下載 Titanic Extended 資料集(Kaggle)
- 18 個特徵工程(Age, Sex, Pclass, FamilySize, Fare…)
- 評估函數:
evaluate_accuracy()(從 bpb 改成 accuracy)
2. train_titanic.py(替換 train.py)
- 模型:從 GPT → MLP classifier
- Loss:從 language modeling → binary cross-entropy
- 超參數:LR, weight decay, batch size…(Agent 可以改的部分)
3. program_titanic.md(替換 program.md)
- 評估指標:從
val_bpb(越低越好)→val_accuracy(越高越好) - 時間預算:從 300 秒 → 30 秒(快速迭代)
- Keep 標準:加入過擬合檢查(overfit_gap < 0.05)
小結
選 Titanic 的原因:大家熟悉、小而快、有驗證、MacBook 能跑。
核心改動:任務(LLM → 分類)、指標(bpb → accuracy)、時間(300s → 30s)。
接下來講 5 個實驗的實際過程。
Chapter 3:實戰過程 — 5 個實驗的故事
我讓 Agent 跑了 5 個實驗,總共 2.5 分鐘。
這是 results_titanic.tsv 的記錄:
| # | LR | WD | val_acc | 狀態 | 描述 |
|---|---|---|---|---|---|
| 1 | 0.01 | 0.1 | 79.78% | ✅ keep | baseline |
| 2 | 0.001 | 0.1 | 79.78% | ❌ discard | 只降 LR(沒用) |
| 3 | 0.001 | 0.01 | 80.90% | ✅ keep | 降 LR + WD(+1.12%)⭐ |
| 4 | 0.0001 | 0.01 | 79.78% | ❌ discard | LR 太低 |
| 5 | 0.005 | 0.05 | 80.34% | ❌ discard | 不如實驗 3 |
接下來一個一個講。
實驗 1:Baseline
Agent 做了什麼:
- 跑原始設定:LR=0.01, WD=0.1
- 30 秒訓練
結果:
- val_acc = 79.78%
- overfit_gap = 0.0227
Agent 決策:
- 這是 baseline,自動 keep
- 記錄到
results_titanic.tsv
我的觀察:
- 79.78% 不算差,但還有空間
- overfit_gap 0.0227 算正常(< 0.05)
實驗 2:只降低學習率
Agent 的想法:
- Baseline 的 LR=0.01 可能太高
- 試試看降到 LR=0.001
修改:
- LR: 0.01 → 0.001
- WD: 保持 0.1
結果:
- val_acc = 79.78%(完全沒變)
- overfit_gap = 0.0213
Agent 決策:
- val_acc 沒改善 → Discard
git reset --hard回到實驗 1
洞察:
- 單獨降 LR 沒用
- 可能是其他因素在限制
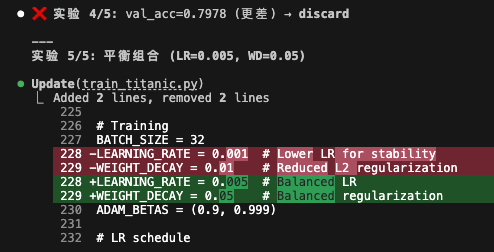
實驗 3:同時降低 LR 和 WD ⭐
Agent 的想法:
- 實驗 2 失敗了,但 LR=0.001 方向可能對
- 會不會是 weight decay 太高(0.1)?
- 試試同時降低
修改:
- LR: 0.01 → 0.001
- WD: 0.1 → 0.01
結果:
- val_acc = 80.90%(+1.12%!)
- val_f1 = 77.03%(+1.69%)
- overfit_gap = 0.0115(減半!)
Agent 決策:
- val_acc 改善 + overfit_gap 降低學習率
- 30 秒足夠找到顯著改善
接下來講我如何客製化 program.md 來實現這些實驗。
Chapter 4:我改了 program.md 的什麼?
為了把 autoresearch 從 LLM 改成 Titanic,我修改了 program.md 的 4 個關鍵部分。
改動 1:評估指標(單一 → 多指標)
原版:
5. Extract results: grep "^val_bpb:" run.log
8. If val_bpb improved → keep
只看一個數字:val_bpb。
我的版本:
5. Extract results: grep "^val_accuracy:\|^val_f1:\|^val_auc:\|^overfit_gap:" run.log
8. Decision:
- Keep if: val_accuracy improved AND overfit_gap < 0.05
- Discard if: val_accuracy worse OR overfitting
看 4 個指標:accuracy、F1、AUC、overfit_gap。
為什麼改?
Classification 任務不能只看 accuracy:
- val_f1:precision/recall 平衡
- val_auc:區分能力
- overfit_gap:過擬合檢查
小數據集(891 樣本)很容易過擬合,overfit_gap 是關鍵。
實際效果:
- 實驗 3:val_acc 提升 + overfit_gap 降低 → 真改善
- 如果只看 accuracy,可能錯過泛化能力變差的問題
改動 2:Keep 標準(加入過擬合檢查)
原版:
If val_bpb improved → keep
只要指標變好就 keep。
我的版本:
Keep if: val_accuracy improved AND overfit_gap = 0.05
加入兩個條件:
- accuracy 要提升
- overfit_gap 必須 長時間訓練(在小任務上)
改動 4:Loop Control(可指定實驗數)
原版:
LOOP FOREVER:
**NEVER STOP**: Do NOT ask if you should continue.
Agent 永遠不會停,直到人類手動中斷。
我的版本:
Loop control:
- Default: Run indefinitely (NEVER STOP)
- If user specifies a number (e.g., "run 5 experiments"):
Stop after N experiments and summarize results
保留 NEVER STOP,但加入可控停止點。
為什麼改?
測試階段需要可控:
- 我說「跑 5 個實驗」→ Agent 跑完 5 個就停
- Agent 自動總結 results_titanic.tsv
- 不會無限跑下去(浪費電腦資源)
生產階段可以用 NEVER STOP(睡覺時跑 100 個實驗)。
改動對照表
| 項目 | 原版 | 我的版本 | 原因 |
|---|---|---|---|
| 評估指標 | val_bpb | val_acc + val_f1 + val_auc + overfit_gap | 分類需要多維度 |
| Keep 標準 | bpb 降低 | acc 提升且不過擬合 | 避免虛假改善 |
| 時間預算 | 固定 300s | 可調整(我用 30s) | 任務彈性 |
| 停止機制 | NEVER STOP | 可指定實驗數 | 測試階段可控 |
program.md 是程式碼,不是文件
這些修改讓我意識到:
program.md 的每一句話都會影響 Agent 行為。
例如:
-
我寫「Keep if val_accuracy improved」
- Agent 會接受 +0.0001 的改善
-
我改成「Keep if val_accuracy improved by at least 0.01」
- Agent 會忽略小於 1% 的改善
這不是「給人看的說明」,而是「給 Agent 執行的規範」。
類比:
- Python 程式碼定義「模型怎麼計算」
- program.md 定義「Agent 怎麼研究」
都是程式,只是語言不同。
小結
我客製化的 4 個關鍵:
- 多指標評估(避免片面優化)
- 過擬合檢查(避免虛假改善)
- 彈性時間預算(適應任務)
- 可控停止點(測試階段友善)
這些改動讓 autoresearch 從「LLM 專用」變成「通用 ML 實驗框架」。
接下來總結洞察和對 ML engineer 的影響。
Chapter 5:洞察與反思 — ML Engineer 的角色轉變
從這次實驗,我學到的不只是「怎麼用 autoresearch」,而是更深層的思考:
當 AI 能自己做實驗,ML Engineer 的價值在哪?
洞察 1:Agent 比你想的更 literal
你寫「improve accuracy」→ Agent 會接受 +0.0001。
你寫「improve by at least 0.01」→ Agent 才會過濾雜訊。
教訓:program.md 不是文件,是程式碼。
每一句話都要精確,不能假設 Agent 會「理解語意」。
就像寫 Python:
if x > 0和if x >= 0差一個等號,行為完全不同- program.md 也是,「improved」和「improved by at least 0.01」差很多
對 ML engineer 的影響:
- 以前:寫 Python code 定義模型
- 現在:寫自然語言「程式」定義研究流程
- 需要的技能:精確表達 + 系統化思維
洞察 2:快速迭代 > 長時間訓練(在某些場景)
我的實驗:
- 5 個實驗 × 30 秒 = 2.5 分鐘 → 找到 +1.12% 改善
- 如果用 300 秒:同樣時間只能跑 0.5 個實驗
關鍵發現:
- 小數據集 + 簡單模型 → 快速迭代效率更高
- 大數據集 + 複雜模型 → 需要長時間訓練
對 ML engineer 的影響:
- 要會判斷「這個任務適合快迭代還是慢訓練」
- 不是所有問題都需要 GPU 跑一整晚
- 實驗設計能力 > 單純調參能力
洞察 3:多指標評估是防護網
只看 accuracy 的問題:
- 可能在 validation set 上過擬合
- 可能犧牲 precision 換 recall
- 上線後爆炸
加入 val_f1, val_auc, overfit_gap:
- 實驗 3 不只 acc 提升,gap 還降低(真改善)
- 多維度檢查 = 更穩健的改善
對 ML engineer 的影響:
- 從「調到指標高」變成「設計評估系統」
- 要會判斷「這個任務該看哪些指標」
- 評估設計能力變得關鍵
洞察 4:Infrastructure matters
這次實驗順利是因為:
- 資料已經準備好(prepare_titanic.py)
- 評估函數寫好了(evaluate_accuracy)
- Git workflow 設定好了
- 30 秒就能跑完一個實驗
如果缺任何一塊:
- 資料沒準備好 → Agent 卡住
- 評估函數有 bug → Agent 拿到錯誤訊號
- Git 設定錯誤 → 實驗歷史亂掉
- 訓練太慢 → 迭代效率低
對 ML engineer 的影響:
- Infrastructure 建設變得更重要
- 以前:自己跑實驗,慢一點沒關係
- 現在:Agent 跑實驗,慢 = 浪費所有時間
- 需要補強:實驗 infra 搭建能力
洞察 5:人類的角色從「研究者」變成「流程設計師」
傳統 ML 工作流程:
人類:調參數 → 跑實驗 → 看結果 → 決定 keep/discard → 重複
autoresearch 工作流程:
人類:設計實驗流程(program.md)
Agent:跑實驗 → 看結果 → 決定 keep/discard → 重複
人類:檢視結果,調整流程
角色轉變:
- 從「執行實驗」變成「設計實驗系統」
- 從「做決策」變成「設計決策規則」
ML Engineer 需要補強什麼?
基於這次實驗,我認為未來 ML engineer 需要這些能力:
1. 實驗設計能力
最重要的能力轉變
- 以前:會調參數(LR, batch size, dropout…)
- 現在:會設計「怎麼調參數的流程」
- 什麼時候該 keep?
- 什麼時候該放棄某個方向?
- 如何避免重複踩坑?
怎麼練:
- 寫 program.md 就是在練
- 思考「如果我是 Agent,這個指令夠明確嗎?」
- 系統化思維 > 直覺
2. 實驗 Infrastructure
決定迭代速度的關鍵
需要建設:
- 快速資料載入(不要每次重新下載)
- 穩定評估函數(不能有 bug)
- Git workflow(自動版本控制)
- 實驗記錄系統(results.tsv + 更多)
- 監控和告警(Agent 卡住要知道)
怎麼練:
- 把手動操作自動化
- 建立「一鍵啟動實驗環境」
- 學 MLOps 工具(DVC, MLflow, W&B…)
3. 評估系統設計
避免虛假改善的防護網
- 單一指標 → 多指標評估
- 只看 validation → 加入過擬合檢查
- 靜態閾值 → 動態閾值(根據任務調整)
怎麼練:
- 多思考「這個指標能被 hack 嗎?」
- 研究不同任務的評估最佳實踐
- 看 Kaggle 比賽的評估設計
4. 精確表達能力
program.md 是程式碼,不是文件
- 模糊:「improve accuracy」
- 精確:「improve accuracy by at least 0.01」
怎麼練:
- 當成寫 spec(技術規格書)
- 每句話都想「Agent 會不會誤解」
- 測試驅動:跑實驗看 Agent 是否照做
5. 模型理解(仍然重要)
不會消失,但佔比降低
- 仍然要懂:什麼模型適合什麼任務
- 但不用:手動調每個超參數
- Agent 負責:探索超參數空間
- 人類負責:定義探索邊界
總結:這不是 AutoML
看到 autoresearch 時,你可能會想:「這不就是 AutoML 嗎?」
其實不是。
autoresearch vs AutoML:核心差異
AutoML(如 AutoGluon, H2O.ai, Auto-sklearn):
- 給你一個黑盒子
- 輸入:資料
- 輸出:最佳模型
- 你不知道它做了什麼,也改不了
autoresearch:
- 給你一個透明的研究流程
- 輸入:資料 + program.md(你定義的研究流程)
- 輸出:實驗歷史 + 最佳模型
- 所有決策都在 git history 裡,可以回溯
關鍵差異:
| 維度 | AutoML | autoresearch |
|---|---|---|
| 控制權 | 黑盒子,不可控 | 透明,完全可控 |
| 彈性 | 固定流程 | 自定義研究流程 |
| 可解釋性 | 不知道為什麼選這個模型 | Git history 記錄所有決策 |
| 適用場景 | 快速原型 | 研究探索 |
| 人類角色 | 提供資料,等結果 | 設計研究流程 |
類比:
- AutoML = 全自動洗衣機(按一個鈕,等結果)
- autoresearch = 半自動洗衣機 + 可客製化流程(你定義洗法,機器執行)
為什麼 autoresearch 更有價值?
1. 可控探索
AutoML 可能會:
- 試了 100 個模型,選最好的(但你不知道其他 99 個長什麼樣)
- 用了複雜的 ensemble(難以部署)
autoresearch:
- 每個實驗都在 git history
- 你可以看到「為什麼 Agent 選這個」
- 可以回到任何一個實驗狀態
2. 學習機會
AutoML:
- 得到一個模型,但不知道為什麼
- 下次遇到類似問題,還是要重跑 AutoML
autoresearch:
- 看
results.tsv可以學到「什麼方向有效」 - 我的實驗:降低 WD 比降低 LR 有效(可遷移的知識)
3. 適應性
AutoML:
- 固定流程,不能改
- 如果你的任務不在它支援範圍內,沒辦法
autoresearch:
- 客製化 program.md 適應任何任務
- 我把 LLM pretraining 改成 Titanic 分類
回到演進
讓我重新整理一下這個演進:
| 時代 | 人類做什麼 | AI 做什麼 | 代表工具 |
|---|---|---|---|
| 傳統開發 | 寫 code + 做決策 | ❌ 無 | 純手動 |
| AI 輔助 | 做決策 | 寫 code | Claude Code, Copilot |
| 自主實驗 | 設計研究流程 | 做決策 + 寫 code | autoresearch |
核心轉變:
- 傳統 → AI 輔助:AI 幫你寫 code
- AI 輔助 → 自主實驗:AI 幫你跑實驗
人類的角色:
- 從「寫 code」變成「做決策」(AI 輔助時代)
- 從「做決策」變成「設計決策流程」(自主實驗時代)
這對未來意味著什麼?
短期(1-2 年):
- autoresearch 還是小眾工具
- 但概念會影響 MLOps 工具設計
- 更多「Agent 自主實驗」的框架會出現
中期(3-5 年):
- ML experiment 平台會內建「Agent 模式」
- 你在 W&B / MLflow 點一個按鈕,Agent 幫你跑 100 個實驗
- program.md 變成標準配置文件
長期(5-10 年):
- Agent 不只做實驗,還會設計研究流程
- 人類的角色:定義「什麼是好的研究」
- 就像現在 AI 會寫 code,但你要定義「什麼是好的軟體」
最後的思考
這次實驗讓我意識到:
工具會變,但思維模式更重要。
autoresearch 可能只是一個實驗性專案,但它代表的思維:
- 把「研究流程」當成可編程的系統
- 用自然語言「程式」定義 Agent 行為
- 讓 AI 自主探索,人類設計邊界
這些概念會持續演進。
5 年前,你可能覺得「讓 AI 寫 code」很科幻。
現在,Claude Code、Copilot 是日常工具。
5 年後,「讓 AI 自己做實驗」可能也會變成常態。
重點不是工具本身,而是學會與 AI 協作的新模式。
從「我寫 code」到「AI 寫 code,我做決策」到「AI 做實驗,我設計流程」。
下一步是什麼?我也不知道。
但至少現在,我們可以開始練習「設計研究流程」這個新技能。
完。
這是我把 autoresearch 從 LLM 改成 Titanic 的實戰筆記。
如果你也想試試看,建議:
- 選一個熟悉的小問題(不要直接上 LLM)
- 客製化 program.md(多指標、過擬合檢查)
- 跑 5-10 個實驗,觀察 Agent 行為
- 調整 program.md,再跑一輪
重點不是「做出最好的模型」,而是「學會設計研究流程」。
這才是 autoresearch 真正的價值。
延伸閱讀
- 不靠直覺,靠實驗:用 AutoResearch 找到 C++ 的 33x 優化空間 — 把同樣的 autoresearch 方法用在 C++ 效能優化,找到 33x 的改善空間
- 把 ML 工程師的直覺,打包進 Agent — 延伸:把 Kaggle top solution 分析的直覺直接封裝進 Agent,讓 ML 工程師的經驗可重複使用
- AI Agent 大語言模型輸出評估:如何選擇最佳評估框架? — 實驗結果怎麼評估:Agent 跑完 100 個實驗之後,如何系統化衡量輸出品質