Self Escalate Agent:刻意設計成不完整的 AI

想像一個場景:你問 agent 今天的天氣,它沒有查詢工具,但它不說——它選擇發明一個答案,附上溫度、濕度、紫外線指數,信心十足。你不知道它在亂說,採信了,出門沒帶傘。
這個問題在 agent 開發裡比想像中常見。大部分系統的設計目標是讓 agent 能回答更多問題,但對「做不到的事該怎麼辦」沒有給出好的答案。靜默失敗或亂猜,兩種結果都很糟。
這篇文章分享一個構想和它的最小實作:self-escalate-agent。
讀完這篇,你會理解:
- 為什麼 “agent 承認做不到” 比 “agent 亂猜” 更有工程價值
- 原型機哲學:一個刻意設計成不完整、靠人機協作長大的 agent
- 如何用 GitHub Issue 作為能力成長的迴路
- 這個系統的最小 Harness 長什麼樣
這是一個 demo,不是成品。目標是拋出一個設計方向,歡迎大家一起討論。
self-escalate-agent 的設計靈感從哪裡來?
self-escalate-agent 的架構靈感來自 hermes-agent,一個更完整的 harness agent 實作,用 skill 自我進化:agent 遇到能力缺口,會自動產生新的 skill 來填補,讓自己下次能更好地處理類似問題。
self-escalate-agent 採用的是另一個方向——把這個進化迴路的控制權交還給人類。
核心問題是:一個 agent,能不能誠實說出「這件事我現在做不到」,然後讓人決定下一步?
這聽起來像是退步,但我認為這才是讓 agent 在真實環境裡可控成長的關鍵。
原型機哲學:為什麼刻意設計一個不完整的 Agent?
原型機哲學的核心是:刻意讓 agent 保持不完整,讓真實環境裡遇到的問題來驅動它的成長,而不是在真空中預先規劃所有能力。有一個比喻很貼切:Gundam 的原型機。
原型機的任務是在實戰中遇到問題、暴露邊界,然後讓工程師根據這些反饋加裝新設備、修改設計。self-escalate-agent 想做的事是這個:
- 遇到能力缺口,不假裝,不繞路
- 開一張 GitHub issue,把問題交給人
- 人看了 issue,決定怎麼填這個缺口(加工具、補 prompt、建新 plugin)
- Agent 下次能做到這件事
每一次 escalation,都是一個精確的改進訊號。累積下來,issue list 就是這個 agent 的能力成長路徑。
這跟 hermes-agent 用 skill 自動進化的方向相反,但也互補:
| 進化方式 | 控制權 | 適合場景 |
|---|---|---|
| Skill 自動進化(hermes-agent) | LLM 自行判斷 | 邊界清晰、可被 LLM 填補的缺口 |
| Issue 人機協作(self-escalate-agent) | 人類決策 | 需要方向決策的缺口 |
自動進化適合邊界清晰的缺口;人機協作適合需要人決策方向的缺口:這個功能要不要做?要怎麼做?現在優先嗎?
SOUL.md:把 Agent 的行為準則從 Code 裡分離
SOUL.md 是一個把 agent 行為準則從程式碼裡獨立出來的文件,讓 agent 的「個性」變成可以版本控制、可以討論的 artifact。系統 prompt 通常被寫死在程式碼裡,或散落在各個字串變數中,SOUL.md 把它變成一個任何人都能讀懂的文件。
## When You Cannot Complete a Task
If you lack the tool or capability to fulfill the user's request:
- Say clearly what you cannot do and why
- **Do NOT suggest workarounds or external links**. That is not your job.
- Tell the user: "This capability isn't available yet."
- Set `converged: false` and `confidence` below 0.3 so the escalation system is triggered.
The right response to a missing capability is escalation, not redirection.改 agent 的行為準則不需要動 Python,只需要改 SOUL.md。更重要的是,把「不能做什麼」寫進 SOUL,讓限制成為設計的一部分,而不是邊緣 case 的事後處理。
自評 JSON:讓 Agent 的狀態可觀測
自評 JSON 是 agent 每次回應後附加的結構化自我評估,讓「agent 是否需要幫助」變成一個顯式的、可追蹤的信號,而不是隱藏在回答文字裡。每次 agent 回應後,它要在回答末尾附上:
{
"converged": true,
"confidence": 0.9,
"reason": "Found a direct answer from a reliable source."
}converged 代表這次回答有沒有真正解決問題,confidence 是 0 到 1 的信心值,reason 是一句解釋。程式碼端解析這段 JSON,決定接下來是繼續對話、標記 resolved,還是觸發 escalation。你可以在 log 裡看到每次對話的 confidence 分佈,找出 agent 最容易卡住的地方——這是一般 agent 系統做不到的可觀測性。
self-escalate-agent 的最小 Harness 長什麼樣?
整個系統只有四個核心部分:SOUL.md 定義行為準則,TaskAgent 跑 LLM 對話迴圈,每次對話的結果存成 Attempt,如果 Attempt 的自評顯示需要協助,Escalator 就觸發 GitHub issue。
Session 代表一次完整對話,Attempt 代表 agent 的一次嘗試,兩者分開讓未來加入 retry 邏輯(在 escalation 之前多試幾次)變得自然。ToolRegistry 用 auto-discovery 讓工具在 import 時自動註冊,擴充或移除工具不需要修改 agent 核心。
Issue 的格式:一張可以被 Triage 的任務單
當 escalation 觸發,agent 把整個對話 context 打包成一張 GitHub issue:
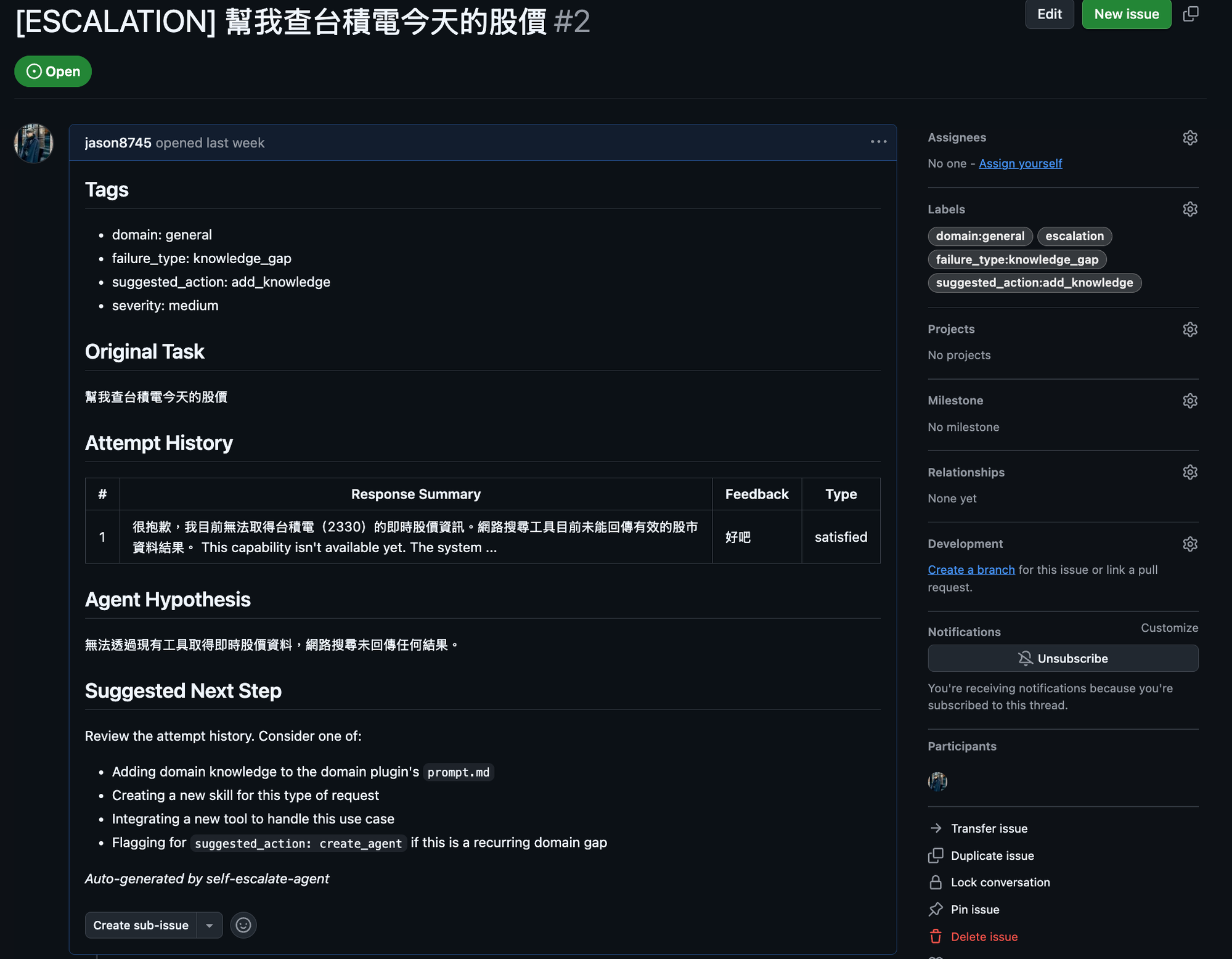
標籤自動打上 escalation、domain:general、failure_type:knowledge_gap。這不只是錯誤報告,它是一張說清楚背景、有明確下一步的任務單,可以被 assign、可以被 close、可以被分析。
Plugin System:兩個維度可以分別替換
Plugin system 由兩個獨立維度組成,分別控制 agent 的專業領域和求援管道,換其中一個不影響另一個。Domain Plugin 讓你切換 agent 的專業領域,只需要提供一個 system prompt 和對應的工具集,安裝一行指令搞定。Escalation Plugin 讓你替換求援的管道,現在內建 GitHub issue,但可以換成 Jira ticket、Linear issue、Slack 通知——任何團隊用來追蹤工作的系統。
Agent 應該越強越好,還是慢慢控制成長?
做這個系統的過程中,我一直在想一個問題:agent 應該一開始越強越好,還是刻意從弱小開始、慢慢控制它的進化?
直覺上,「越強越好」有它的道理。現在的 LLM 底層能力已經很強,限制它反而可能是在人為製造障礙,讓使用者體驗變差。讓 agent 先跑起來、出了問題再修,似乎比謹慎地一步步加功能更有效率。
但我又覺得這個直覺在某些情境下會出問題。一個「很強」的 agent,出錯的時候往往更難被發現——它給的答案看起來更有說服力,使用者更容易採信。能力越強,hallucination 的傷害半徑也越大。self-escalate-agent 的設計邏輯,某種程度上是在說:我寧願讓 agent 先暴露它的邊界,再讓人決定要不要填補。
但我沒有辦法說這個方向一定對。不同 domain 對「控制」和「穩定性」的要求差異很大。一個內部知識庫查詢工具,出錯的成本低,「越強越好」可能完全合理。一個醫療或法律場景的 agent,每一次錯誤都有真實代價,慢慢控制進化可能才是唯一負責任的做法。通用助手跟垂直領域工具,需要的成長策略可能根本就是兩件事。
這個 repo 是個小小的構想,主要想拋出「透過 Issue 讓 agent 成長」這個方向。如果你有在做類似的事,或者對「agent 應該怎麼成長」這個問題有想法,歡迎開 issue 或留言討論。